
If you can’t measure it, you can’t improve it. It’s true for your business, and it’s true for your digital platform. Yet we’ve seen organizations from startups to enterprises neglect to incorporate measurement into their platform strategy.
Data shows you what is and isn’t working in your platform. And, unlike most websites, platforms provide detailed information about known users across specific touchpoints — accurate, first-party data that doesn’t rely on cookies or fuzzy analytics. Actionable insights await; you just have to know what you’re measuring for.
Here’s how to take a strategic approach to measuring platform performance.
Start From the Top
Measuring the success of your platform involves the same general principles used in strategic planning. Start from the top and work your way down:
- What are your organization’s overall goals?
- What are the business objectives that drive those goals?
- What does your platform need to accomplish, in order to support those objectives?
- What is the core purpose your platform must meet to achieve its goals?
Once you define your platform’s core purpose, you can identify which metrics to track. Just make sure that if you move the needle on those metrics, you’re truly moving the needle for your business.
Here’s an example: Let’s say you run a healthcare system whose primary goal is to save lives. To meet that goal, your employees need speedy access to your procedures for patient care. So, you build an intranet platform in order to provide the fastest possible access to that critical information. Your core purpose is to make sure this information is as easy to find as possible, so employees have critical information at critical moments.
What Should You Measure?
You’ve identified your platform’s core purpose. Next question is, what is the core interaction your platform relies on to achieve that purpose? What’s the single most important thing you need users to do? That action determines how you define an “active” platform user, and it’s the key driver for what you should measure.
Just like with social media, where the term “monthly active users” is widely used but has many different meanings, business platforms often have unique definitions of an active user. A company intranet focused on employee engagement might define an active user as someone who posts content a certain number of times per month. A business platform offering exclusive deals to attract new customers might define an active user as a customer who redeems at least one deal per year.
Whatever your platform’s purpose is, you need to be tracking metrics related to your definition of an active user, in order to optimize the core interaction that drives your business goals.
Examples of Useful Metrics
Before we dive into the list, there’s a caveat: Just because you can measure a ton of metrics doesn’t mean you should. Too much data can be distracting, and paying attention to too many metrics can create confusion and cause analysis paralysis. The goal of measurement isn’t to manage a dashboard; it’s to make decisions and take actions that drive positive business outcomes.
Choose a primary goal, define a core objective and active user, and aim for up to five core metrics to measure success. Here are some examples:
Growth
If your business goals depend on having a large number of platform users, you might use one of the following growth measures:
- Total number of users over time
- Rate at which new people join the platform
- Rate of user attrition in a given period
Reach
This is useful for platforms where you’re looking to engage a certain proportion of a population, such as your employees or your customer base. You might track:
- Total number of registered users
- Percentage of total registered users that are active
- Total logins versus unique logins
Engagement
Engagement covers a lot of ground, and it’s easy to get lost in the weeds. Focus on the metrics that tell you how people are responding to your efforts to engage them at various touchpoints. Here are some examples:
- Number of posts per user / Average number of responses per post
- Number of unique users completing an action, like submitting a form
- Number of support requests (are users confused?)
Begin at the Beginning
It’s a mistake to think about measurement only after you’ve built your platform. Remember, platform measurement isn’t as easy as dropping in base Google Analytics code. Platform metrics are deep and nuanced, so you need to think strategically from the start. Plan the key metrics up front, and incorporate measurement into your platform roadmap from the beginning.
Your game plan, in a nutshell:
- Decide what to measure
- Implement tracking capabilities
- Measure platform performance
- Analyze the results and find actionable insights
- Make decisions: what’s working, and what needs to change?
Establishing measurement practices early on enables you to continually track, analyze, and optimize performance over the life of your platform. Already launched? Fear not. It’s never too late to implement measurement techniques to optimize platform performance.
If you’re thinking about how to be more strategic with platform measurement, we’d love to help. Feel free to reach out with any questions you have.
Why are microservices growing in popularity for enterprise-level platforms? For many organizations, a microservice architecture provides a faster and more flexible way to leverage technology to meet evolving business needs. For some leaders, microservices better reflect how they want to structure their teams and processes.
But are microservices the best fit for you?
We’re hearing this question more and more from platform owners across multiple industries as software monoliths become increasingly impractical in today’s fast-paced competitive landscape. However, while microservices offer the agility and flexibility that many organizations are looking for, they’re not right for everyone.
In this article, we’ll cover key factors in deciding whether microservices architecture is the right choice for your platform.
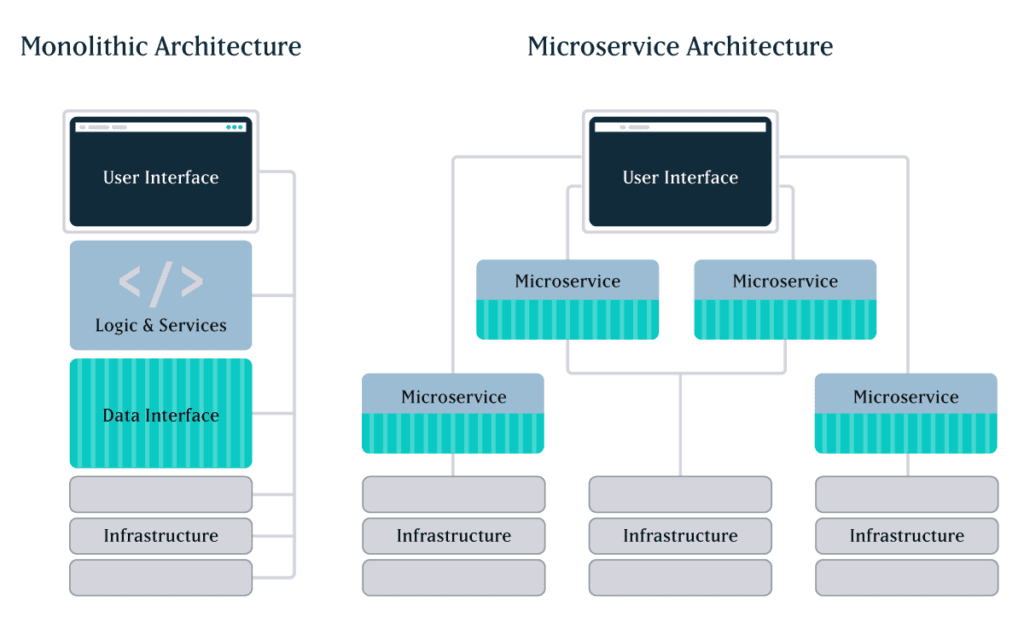
What’s the Difference Between Microservices and Monoliths?
Microservices architecture emerged roughly a decade ago to address the primary limitations of monolithic applications: scale, flexibility, and speed.
Microservices are small, separately deployable, software units that together form a single, larger application. Specific functions are carried out by individual services. For example, if your platform allows users to log in to an account, search for products, and pay online, those functions could be delivered as separate microservices and served up through one user interface (UI).
In monolithic architecture, all of the functions and UI are interconnected in a single, self-contained application. All code is traditionally written in one language and housed in a single codebase, and all functions rely on shared data libraries.
Essentially, with most off-the-shelf monoliths, you get what you get. It may do everything, but not be particularly great at anything. With microservices, by contrast, you can build or cherry-pick optimal applications from the best a given industry has to offer.
Because of their modular nature, microservices make it easier to deploy new functions, scale individual services, and isolate and fix problems. On the other hand, with less complexity and fewer moving parts, monoliths can be cheaper and easier to develop and manage.
So which one is better? As with most things technological, it depends on many factors. Let’s take a look at the benefits and drawbacks of microservices.
Advantages of Microservices Architecture
Companies that embrace microservices see it as a cleaner, faster, and more efficient approach to meeting business needs, such as managing a growing user base, expanding feature sets, and deploying solutions quickly. In fact, there are a number of ways in which microservices beat out monoliths for speed, scale, and agility.
Shorter time to market
Large monolithic applications can take a long time to develop and deploy, anywhere from months to years. That could leave you lagging behind your competitors’ product releases or struggling to respond quickly to user feedback.
By leveraging third-party microservices rather than building your own applications from scratch, you can drastically reduce time to market. And, because the services are compartmentalized, they can be built and deployed independently by smaller, dedicated teams working simultaneously. You also have greater flexibility in finding the right tools for the job: you can choose the best of breed for each service, regardless of technology stack.
Lastly, microservices facilitate the minimum viable product approach. Instead of deploying everything on your wishlist at once, you can roll out core services first and then release subsequent services later.
Faster feature releases
Any changes or updates to monoliths require redeploying the entire application. The bigger a monolith gets, the more time and effort is required for things like updates and new releases.
By contrast, because microservices are independently managed, dedicated teams can iterate at their own pace without disrupting others or taking down the entire system. This means you can deploy new features rapidly and continuously, with little to no risk of impacting other areas of the platform.
This added agility also lets you prioritize and manage feature requests from a business perspective, not a technology perspective. Technology shouldn’t prevent you from making changes that increase user engagement or drive revenue—it should enable those changes.
Affordable scalability
If you need to scale just one service in a monolithic architecture, you’ll have to scale and redeploy the entire application. This can get expensive, and you may not be able to scale in time to satisfy rising demand.
Microservices architecture offers not only greater speed and flexibility, but also potential savings in hosting costs, because you can independently scale any individual service that’s under load. You can also configure a single service to add capability automatically until load need is met, and then scale back to normal capacity.
More support for growth
With microservices architecture, you’re not limited to a UI that’s tethered to your back end. For growing organizations that are continually thinking ahead, this is one of the greatest benefits of microservices architecture.
In the past, websites and mobile apps had completely separate codebases, and launching a mobile app meant developing a whole new application. Today, you just need to develop a mobile UI and connect it to the same service as your website UI. Make updates to the service, and it works across everything.
You have complete control over the UI — what it looks like, how it functions for the customer, etc… You can also test and deploy upgrades without disrupting other services. And, as new forms of data access and usage emerge, you have readily available services that you can use for whatever application suits your needs. Digital signage, voice commands for Alexa… and whatever comes next.
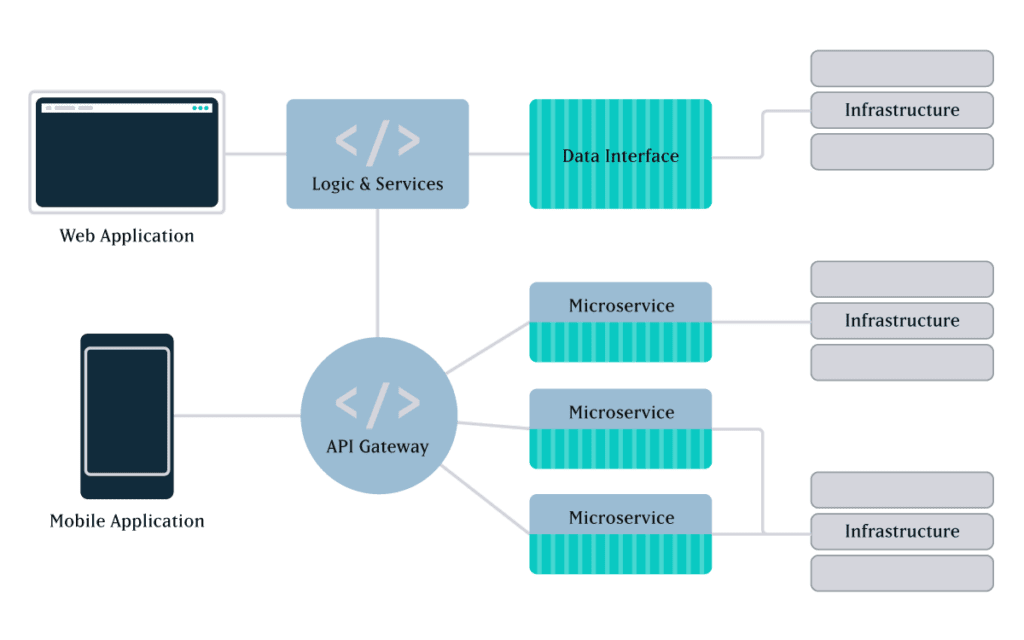
Optimal programming options
Since monolithic applications are tightly coupled and developed with a single stack, all components typically share one programming language and framework. This means any future changes or additions are limited to the choices you make early on, which could cause delays or quality issues in future releases.
Because microservices are loosely coupled and independently deployed, it’s easier to manage diverse datasets and processing requirements. Developers can choose whatever language and storage solution is best suited for each service, without having to coordinate major development efforts with other teams.
Greater resilience
For complex platforms, fault tolerance and isolation are crucial advantages of microservices architecture. There’s less risk of system failure, and it’s easier and faster to fix problems.
In monolithic applications, even just one bug affecting one tiny part of a single feature can cause problems in an unrelated area—or crash the entire application. Any time you make a change to a monolithic application, it introduces risk. With microservices, if one service fails, it’s unlikely to bring others down with it. You’ll have reduced functionality in a specific capacity, not the whole system.
Microservices also make it easier to locate and isolate issues, because you can limit the search to a single software module. Whereas in monoliths, given the possible chain of faults, it’s hard to isolate the root cause of problems or predict the outcome of any changes to the codebase.
Monoliths thus make it difficult and time-consuming to recover from failures, especially since, once an issue has been isolated and resolved, you still have to rebuild and redeploy the entire application. Since microservices allow developers to fix problems or roll back buggy updates in just one service, you’ll see a shorter time to resolution.
Faster onboarding
With smaller, independent code bases, microservices make it faster and easier to onboard new team members. Unlike with monoliths, new developers don’t have to understand how every service works or all the interdependencies at play in the system.
This means you won’t have to scour the internet looking for candidates who can code in the only language you’re using, or spend time training them in all the details of your codebase. Chances are, you’ll find new hires more easily and put them to work faster.
Easier updates
As consumer expectations for digital experiences evolve over time, applications need to be updated or upgraded to meet them. Large monolithic applications are generally difficult, and expensive, to upgrade from one version to the next.
Because third-party app owners build and pay for their own updates, with microservices there’s no need to maintain or enhance every tool in your system. For instance, you get to let Stripe perfect its payment processing service while you leverage the new features. You don’t have to pay for future improvements, and you don’t need anyone on staff to be an expert in payment processing and security.
Disadvantages of Microservices Architecture
Do microservices win in every circumstance? Absolutely not. Monoliths can be a more cost-effective, less complicated, and less risky solution for many applications. Below are a few potential downsides of microservices.
Extra complexity
With more moving parts than monolithic applications, microservices may require additional effort, planning, and automation to ensure smooth deployment. Individual services must cooperate to create a working application, but the inherent separation between teams could make it difficult to create a cohesive end product.
Development teams may have to handle multiple programming languages and frameworks. And, with each service having its own database and data storage system, data consistency could be a challenge.
Also, when you choose to leverage numerous 3rd party services, this creates more network connections as well as more opportunities for latency and connectivity issues in your architecture.
Difficulty in monitoring
Given the complexity of microservices architecture and the interdependencies that may exist among applications, it’s more challenging to test and monitor the entire system. Each microservice requires individualized testing and monitoring.
You could build automated testing scripts to ensure individual applications are always up and running, but this adds time and complexity to system maintenance.
Added external risks
There are always risks when using third-party applications, in terms of both performance and security. The more microservices you employ, the more possible points of failure exist that you don’t directly control.
In addition, with multiple independent containers, you’re exposing more of your system to potential attackers. Those distributed services need to talk to one another, and a high number of inter-service network communications can create opportunities for outside entities to access your system.
On an upside, the containerized nature of microservices architecture prevents security threats in one service from compromising other system components. As we noted in the advantages section above, it’s also easier to track down the root cause of a security issue.
Potential culture changes
Microservices architecture usually works best in organizations that employ a DevOps-first approach, where independent clusters of development and operations teams work together across the lifecycle of an individual service. This structure can make teams more productive and agile in bringing solutions to market. But, at an organizational level, it requires a broader skill set for developing, deploying, and monitoring each individual application.
A DevOps-first culture also means decentralizing decision-making power, shifting it from project teams to a shared responsibility among teams and DevOps engineers. The goal is to ensure that a given microservice meets a solution’s technical requirements and can be supported in the architecture in terms of security, stability, auditing, etc…
3 Paths Toward Microservices Transformation
In general, there are three different approaches to developing a microservices architecture:
1. Deconstruct a monolith
This kind of approach is most common for large enterprise applications, and it can be a massive undertaking. Take Airbnb, for instance: several years ago, the company migrated from a monolith architecture to a service-oriented architecture incorporating microservices. Features such as search, reservations, messaging, and checkout were broken down into one or more individual services, enabling each service to be built, deployed, and scaled independently.
In most cases, it’s not just the monolith that becomes decentralized. Organizations will often break up their development group, creating smaller, independent teams that are responsible for developing, testing, and deploying individual applications.
2. Leverage PBCs
Packaged Business Capabilities, or PBCs, are essentially autonomous collections of microservices that deliver a specific business capability. This approach is often used to create best-of-breed solutions, where many services are third-party tools that talk to each other via APIs.
PBCs can stand alone or serve as the building blocks of larger app suites. Keep in mind, adding multiple microservices or packaged services can drive up costs as the complexity of integration increases.
3. Combine both types
Small monoliths can be a cost-effective solution for simple applications with limited feature sets. If that applies to your business, you may want to build a custom app with a monolithic architecture.
However, there are likely some services, such as payment processing, that you don’t want to have to build yourself. In that case, it often makes sense to build a monolith and incorporate a microservice for any features that would be too costly or complex to tackle in-house.
A Few Words of Caution
Even though they’re called “microservices”, be careful not to get too small. If you break services down into many tiny applications, you may end up creating an overly complex application with excessive overhead. Lots of micro-micro services can easily become too much to maintain over time, with too many teams and people managing different pieces of an application.
Given the added complexity and potential costs of microservices, for smaller platforms with only one UI it may be best to start with a monolithic application and slowly add microservices as you need them. Start at a high level and zoom in over time, looking for specific functions you can optimize to make you stand out.
Lastly, choose your third party services with care. It’s not just about the features; you also need to consider what the costs might look like if you need to scale a particular service.
Final Thoughts: Micro or Mono?
Still trying to decide which architecture is right for your platform? Here are some of the most common scenarios we encounter with clients:
- If time to market is the most important consideration, then leveraging 3rd party microservices is usually the fastest way to build out a platform or deliver new features.
- If some aspect of what you’re doing is custom, then consider starting with a monolith and either building custom services or using 3rd parties for areas that will help suit a particular need.
- If you don’t have a ton of money, and you need to get something up quick and dirty, then consider starting with a monolith and splitting it up later.
Here at Oomph, we understand that enterprise-level software is an enormous investment and a fundamental part of your business. Your choice of architecture can impact everything from overhead to operations. That’s why we take the time to understand your business goals, today and down the road, to help you choose the best fit for your needs.
We’d love to hear more about your vision for a digital platform. Contact us today to talk about how we can help.
How we leveraged Drupal’s native API’s to push notifications to the many department websites for the State.RI.gov is a custom Drupal distribution that was built with the sole purpose of running hundreds of department websites for the state of Rhode Island. The platform leverages a design system for flexible page building, custom authoring permissions, and a series of custom tools to make authoring and distributing content across multiple sites more efficient.
Come work with us at Oomph!
VIEW OPEN POSITIONS
The Challenge
The platform had many business requirements, and one stated that a global notification needed to be published to all department sites in near real-time. These notifications would communicate important department information on all related sites. Further, these notifications needed to be ingested by the individual websites as local content to enable indexing them for search.
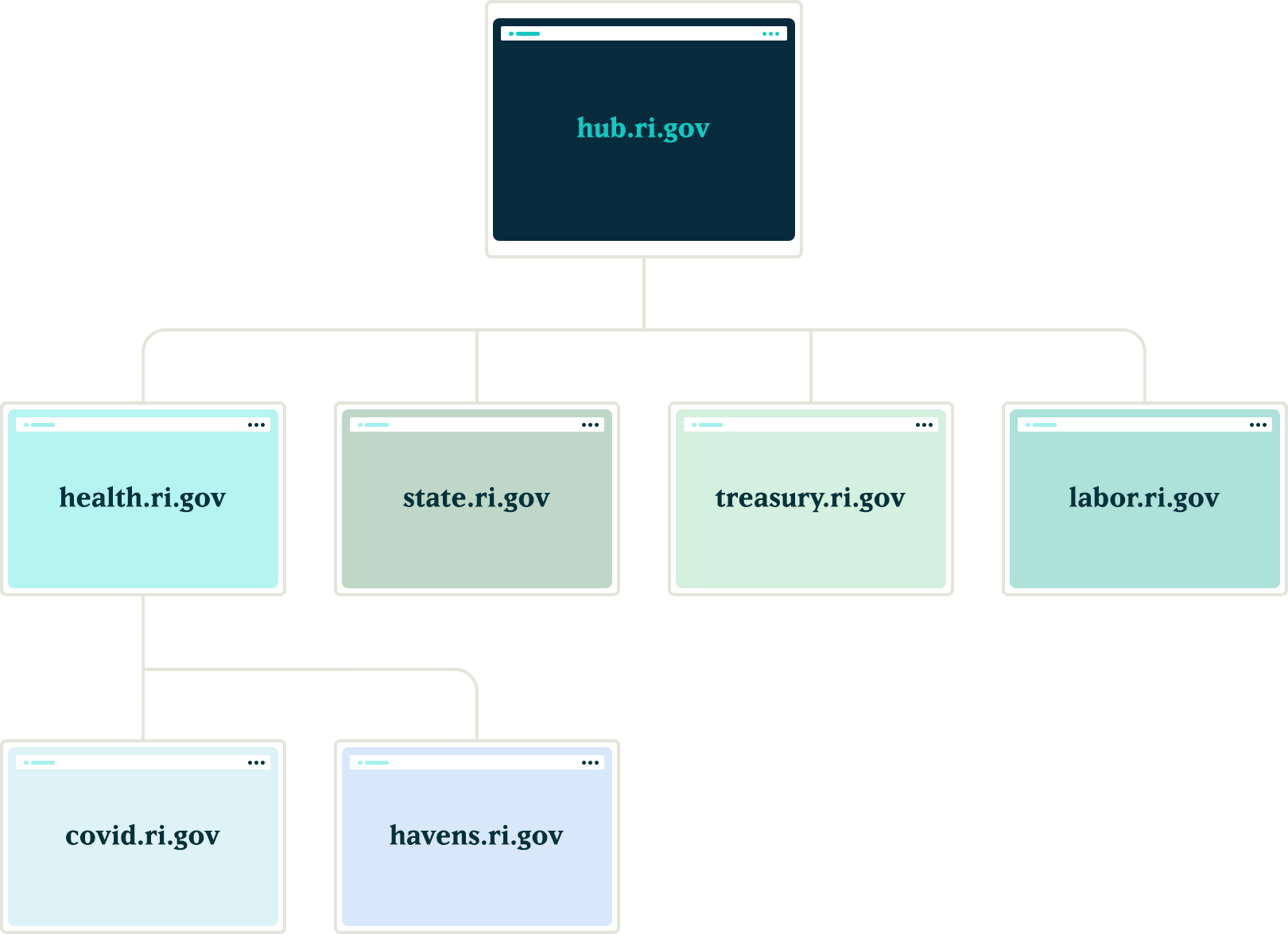
The hierarchy of the departments and their sites added a layer of complexity to this requirement. A department needs to create notifications that broadcast only to subsidiary sites, not the entire network. For example, the Department of Health might need to create a health department specific notification that would get pushed to the Covid site, the RIHavens site, and the RIDelivers sites — but not to an unrelated department, like DEM.
Exploration
Aggregator:
Our first idea was to utilize the built in Drupal aggregator module and pull notifications from the hub. A proof of concept proved that while it worked well for pulling content from the hub site, it had a few problems:
- It relied heavily on the local site’s cron job to pull updates, which led to timing issues in getting the content — it was not in near real-time. Due to server limitations, we could not run cron as often as would be necessary
- Another issue with this approach was that we would need to maintain two entity types, one for global notifications and a second for local site notifications. Keeping local and global notifications as the same entity allowed for easier maintenance for this subsystem.
Feeds:
Another thought was to utilize the Feeds module to pull content from the hub into the local sites. This was a better solution than the aggregator because the nodes would be created locally and could be indexed for local searching. Unfortunately, feeds relied on cron as well.
Our Solution
JSON API
We created a suite of custom modules that centered around moving data between the network sites using Drupal’s JSON API. The API was used to register new sites to the main hub when they came online. It was also used to pass content entities from the main hub down to all sites within the network and from the network sites back to the hub.
Notifications
In order to share content between all of the sites, we needed to ensure that the data structure was identical on all sites in the network. We started by creating a new notification content type that had a title field, a body field, and a boolean checkbox indicating whether the notification should be considered global. Then, we packaged the configuration for this content type using the Features module.
By requiring our new notification feature module in the installation profile, we ensured that all sites would have the required data structure whenever a new site was created. Features also allowed us to ensure that any changes to the notification data model could be applied to all sites in the future, maintaining the consistency we needed.
Network Domain Entity
In order for the main hub, ri.gov, to communicate with all sites in the network, we needed a way to know what Drupal sites existed. To do this, we created a custom configuration entity that stored the URL of sites within the network. Using this domain entity, we were able to query all known sites and passed the global notification nodes created on ri.gov to each known site using the JSON API.
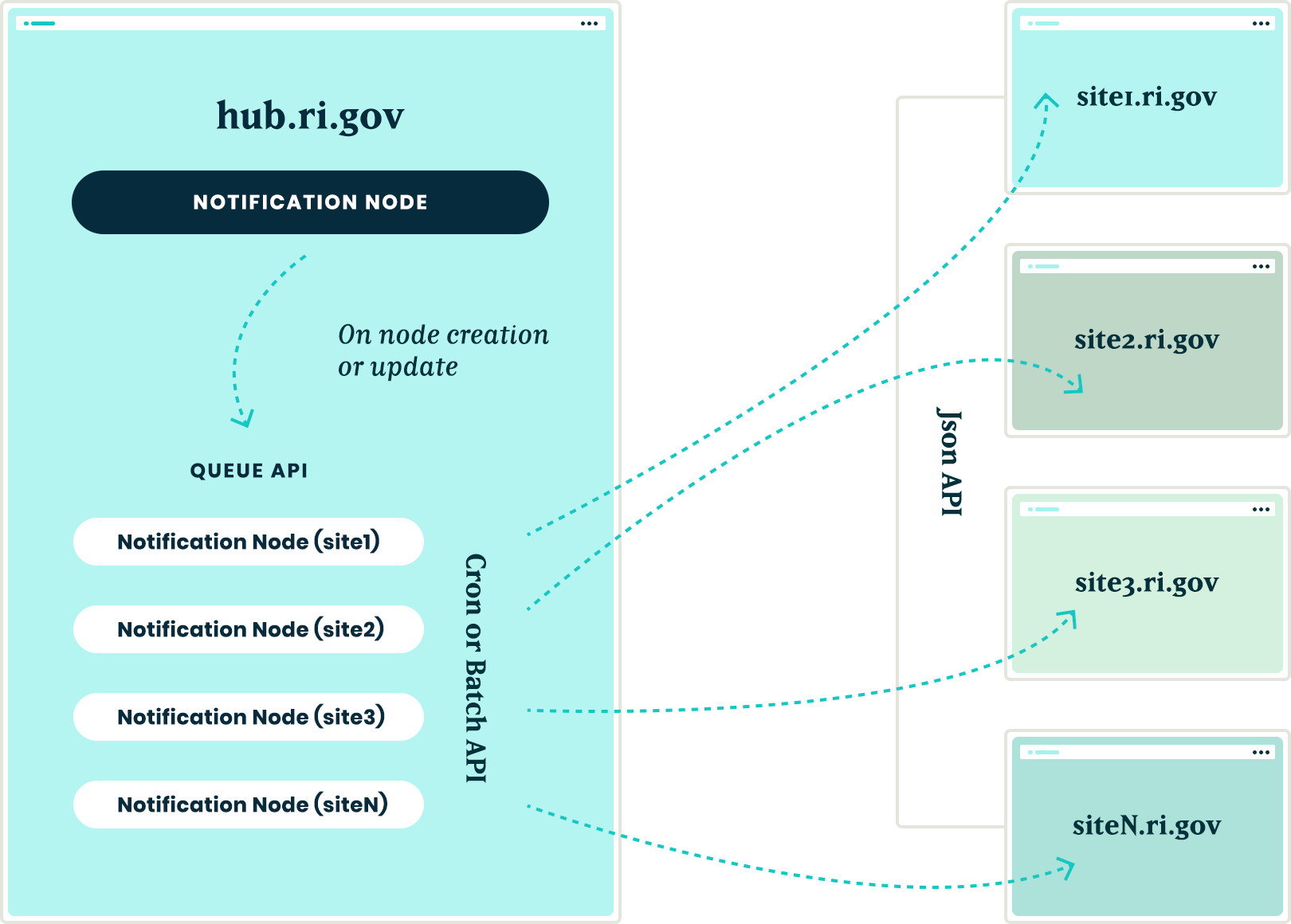
Queue API:
To ensure that the notification nodes were posted to all the sites without timeouts, we decided to utilize Drupal’s Queue API. Once the notification content was created on the ri.gov hub, we queried the known domain entities and created a queue item that would use cron to actually post the notification node to each site’s JSON API endpoint. We decided to use cron in this instance to give us some assurance that a post to many websites wouldn’t timeout and fail.
Batch API
To allow for time sensitive notifications to be pushed immediately, we created a custom batch operation that reads all of the queued notifications and pushes them out one at a time. If any errors are encountered, the notification is re-queued at the end of the stack and the process continues until all notifications have been posted to the network sites.
New site registrations
In order to ensure that new sites receive notifications from the hub, we needed a site registration process. Whenever a new site is spun up, a custom module is installed that calls out to the hub using JSON API and registers itself by creating a new network domain entity with it’s endpoint URL. This allows the hub to know of the new site and can push any new notifications to this site in the future.
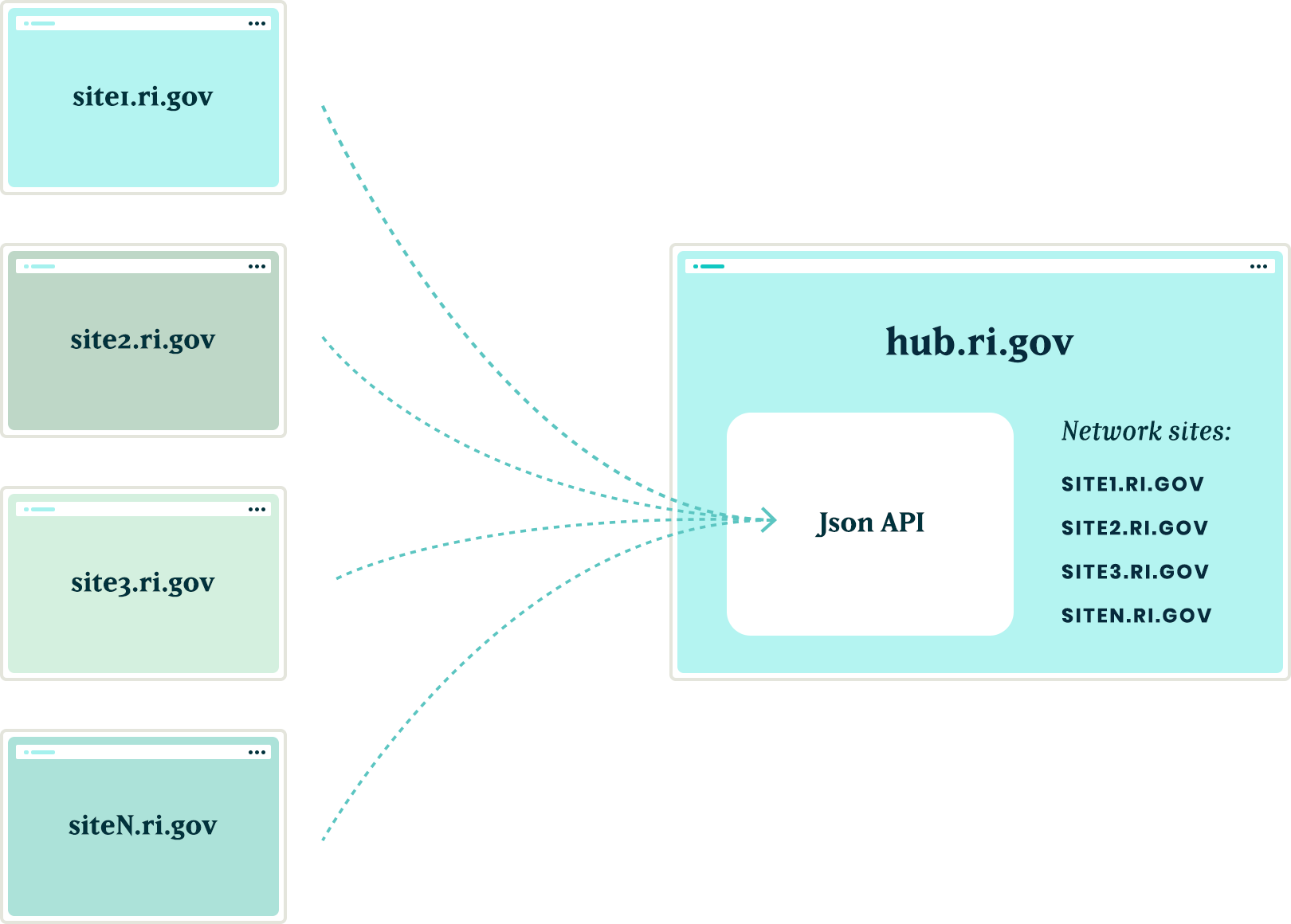
The installation process will also query the hub for any existing notifications and, using the JSON API, get a list of all notification nodes from the hub to add them to it’s local queue for creation. Then, the local site uses cron to query the hub and get the details of each notification node to create it locally. This ensured that when a new site comes online, it will have an up to date list of all the important notifications from the hub.
Authentication
Passing this data between sites is one challenge, but doing it securely adds another layer of complexity. All of the requests going between the sites are authenticating with each other using the Simple Oauth module. When a new site is created, an installation process creates a dedicated user in the local database that will own all notification nodes created with the syndication process. The installation process also creates the appropriate Simple OAuth consumers which allows the authenticated connections to be made between the sites.
Department sites
Once all of the groundwork was in place, with minimal effort, we were able to allow for department sites to act as hubs for their own department sites. Thus, the Department of Health can create notifications that only go to subsidiary sites, keeping them separate from adjacent departments.
Translations
The entire process also works with translations. After a notification is created in the default language, it gets queued and sent to the subsidiary sites. Then, a content author can create a translation of that same node and the translation will get queued and posted to the network of sites in the same manner as the original. All content and translations can be managed at the hub site, which will trickle down to the subsidiary sites.
Moving in the opposite direction
With all of the authorization, queues, batches, and the API’s in place, the next challenge was making this entire system work with a Press Release content type. This provided two new challenges that we needed to overcome:
- Instead of moving content from the top down, we needed to move from the bottom up. Press release nodes get created on the affiliate sites and would need to be replicated on the hub site.
- Press release nodes were more complex than the notification nodes. These content types included media references, taxonomy term references and toughest of all, paragraph references.
Solving the first challenge was pretty simple – we were able to reuse the custom publishing module and instructed the queue API to send the press release nodes to the hub sites.
Getting this working with a complex entity like the press release node meant that we needed to not only push the press release node, but we also needed to push all entities that the initial node referenced. In order for it all to work, the entities needed to be created in reverse order.
Once a press release node was created or updated, we used the EntityInterface referencedEntities() method to recursively drill into all of the entities that were referenced by the press release node. In some cases, this meant getting paragraph entities that were nested two, three, even four levels deep inside of other paragraphs. Once we reached the bottom of the referenced entity pile, we began queuing those entities from the bottom up. So, the paragraph that was nested four levels deep was the first to get sent and the actual node was the last to get sent

Are you a developer looking to grow your skills? Join our team.
Conclusion
Drupal’s powerful suite of API’s gave us all the tools necessary to come up with a platform that will allow the State of Rhode Island to easily keep their citizens informed of important information, while allowing their editing team the ease of a create once and publish everywhere workflow.
Our team recently worked through the first phase of a large government platform run by a component design system. The goals were to create a set of visual themes that could support accessibility, native light- and dark-mode switching, and a set of content components that were flexible enough to support more than 70 government agencies. There is quite a bit of complexity to the system, but what we’d like to focus on right now is how we are managing the color system.
The sites are still evolving, but the current count is five color themes, each with a light- and dark-mode, using a total of 46 colors. We decided to use PatternLab to manage our design patterns, which means that each component is comprised of its own Sass, JS, and Twig files packaged together in a portable way. It also means that we could leverage custom Gulp processes to make some pretty cool stuff happen.
First, our goals of using PatternLab and creating a single source of truth:
- Define a color once and in one place and make its definition available to Sass and Twig
- Define color themes once and in one place and make those definitions available to Sass, Twig, and PHP
- Define colors in HSL(), which is more human-readable, making it easy to understand the relationships between colors, while allowing conversion to whatever color space we might need
For the government employee using this system, our goals were to:
- Allow authors the choice of background colors from defined theme options without controlling foreground colors — this takes the ability to create inaccessible color combinations out of their hands
- Allow authors to design content for their own preferred color scheme (light or dark) and be confident that it will look great for those who use the other mode
And for the end-user viewing any of these sites, we wanted to support:
- A minimum color contrast ratio of 4.5 for accessibility in menus and design components but a higher contrast for main content
- A dark mode that responds to a viewer’s system preference but can also be overridden with local site controls
Here’s how we were able to achieve those goals.
One (H)JSON file to rule them all
We decided that our single source of truth needed to be in a flexible and simple format. JSON fit our needs the best with its ability to support nested relationships and arrays. The only thing it didn’t allow was comments, which can add legibility and documentation. We found that HJSON was a great compromise, and used Gulp to convert our master HJSON file to JSON as part of the build process1.
The HJSON file is one large array. Colors are defined one level deep alongside themes, which are also one level deep. The first level of the structure looks like this:
{
"colors": { … }
"themes": [ … }
}
JSON
Color Definitions
Simple so far. Inside the colors array, individual definitions are structured as a single-depth array:
{
"colors":
# Medium blue
"ocean--dark": {
"name": "Ocean State dark",
"hue": "medium blue",
"hsl": "hsl(208, 12%, 32%)",
"needs": "light-text"
},
"ocean": {
"name": "Ocean State",
"hue": "medium blue",
"hsl": "hsl(208, 54%, 73%)",
"needs": "dark-text"
},
"ocean--light": {
"name": "Ocean State light",
"hue": "light blue",
"hsl": "hsl(208, 58%, 92%)",
"needs": "dark-text"
},
"ocean--trans25": {
"name": "Ocean State 25% transparent",
"hue": "medium blue",
"hsl": "hsla(208, 54%, 73%, 0.25)",
"needs": "dark-text"
}
}
}
JSON
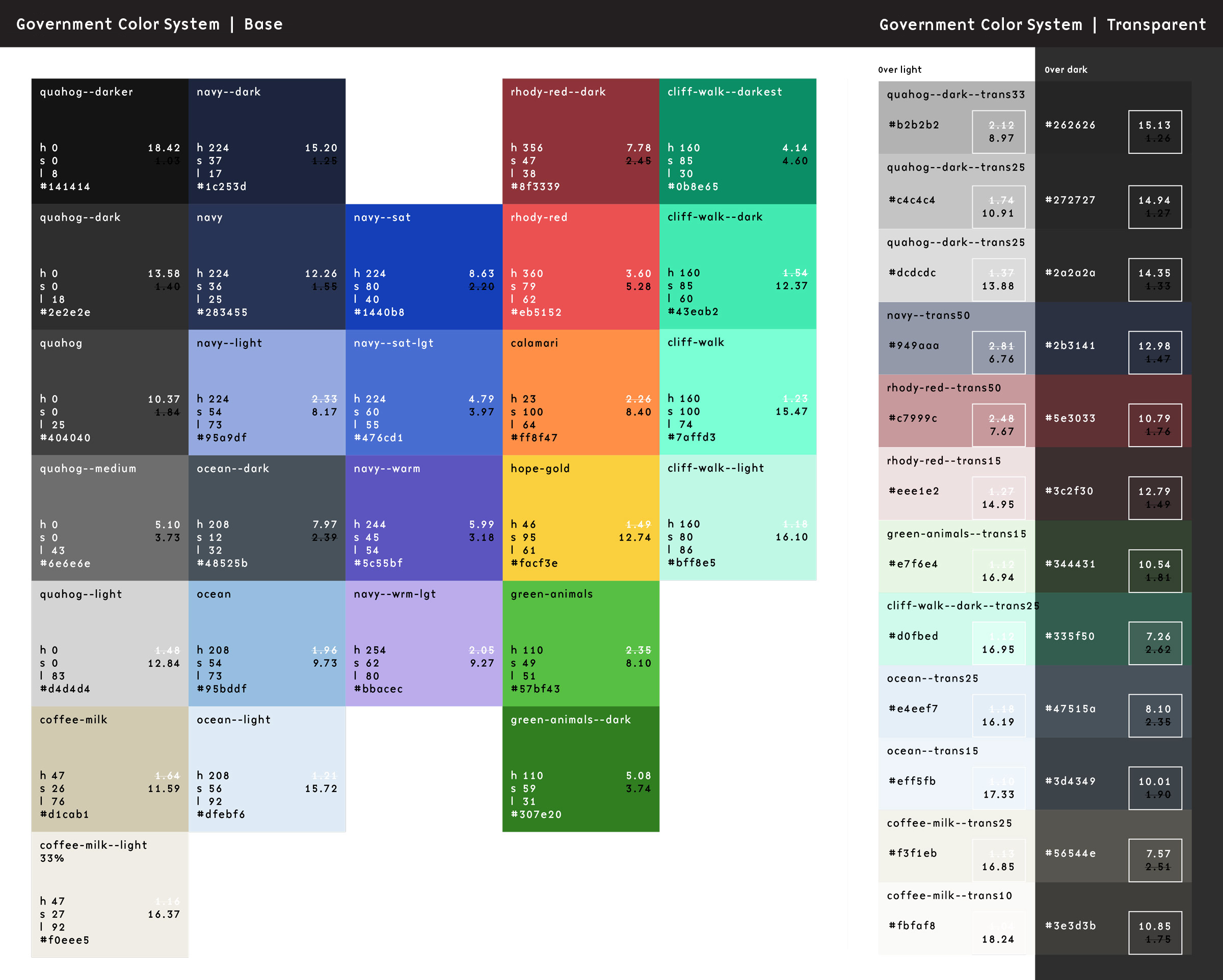
There are 46 colors total, but they all follow this pattern2. The first key is the name of the color, written in a slug form that will work in Sass and Twig. We like BEM, so the naming of our colors follow a similar idea. We tried to keep naming things easy, so once a color name is established, its variations are “–darker”, “–dark”, “–light”, with some colors using variations like “–bright” or “–trans25”.
Within each color definitions are the following bits of data:
- name: A human-readable name that can be used in a select list
- hue: How the color might be described
- hsl: The actual color definition in either the HSL() or the HSLA() color space
- needs: What color text would this color need? Light or dark are the values we expect here
Outside of Pattern Lab, the colors in our system are represented by this preview from our documentation:
Turning HJSON Colors into Sass
Now the fun begins.
With our custom Gulp process, these HJSON definitions get turned into minified JSON. This happens as part of the initial build time. Once that JSON is created, when our Sass is saved and a new compilation happens, the contents of that JSON file are available to the Sass build process as a large Sass array. That allows a Sass file to define all of these colors as custom properties:
In a file called _colors.scss, we use an @each loop to write them all into our stylesheet as CSS custom properties on the HTML element3:
html {
/* Default color CSS vars */
@each $key, $value in $colors {
--c__#{$key}: #{map-get($value, hsl)};
}
}
Sass (Scss)
The output looks as you might expect. The Gulp process converts the colors from the HSL color space into the more typical Hexidecimal and RGBA color spaces:
html {
--c__ocean--dark: #48525b;
--c__ocean: #95bddf;
--c__ocean--light: #dfebf6;
--c__ocean--trans25: rgba(149, 189, 223, 0.25);
}
CSS
Turning HJSON Colors into Twig
That’s pretty cool, but it gets cooler. In a design system tool like Pattern Lab, we want to display swatches of these colors to end users of the design system. This is where the same ideas as converting JSON to Sass can be applied inside Twig files. The JSON file is read into and available as an array as well, which allows a colors.twig file to do this:
<ul class="sg-colors">
{% for key, color in colors %}
<li>
<span class="sg-swatch" style="background: {{ color.hsl }};"></span>
<span class="sg-label"><b>{{ color.name }}:</b> {{ color.hsl }}</span>
<span class="sg-code"><code>var(--c__{{ key }})</code></span>
</li>
{% endfor %}
</ul>
Twig
A for loop in Twig iterates on the array and outputs a color swatch, a human-readable label, and the name of the CSS custom property. Pretty neat! Now we can update our colors in the HJSON file and those changes trickle down to the Sass definition and the Twig preview as well as our CSS stylesheet.
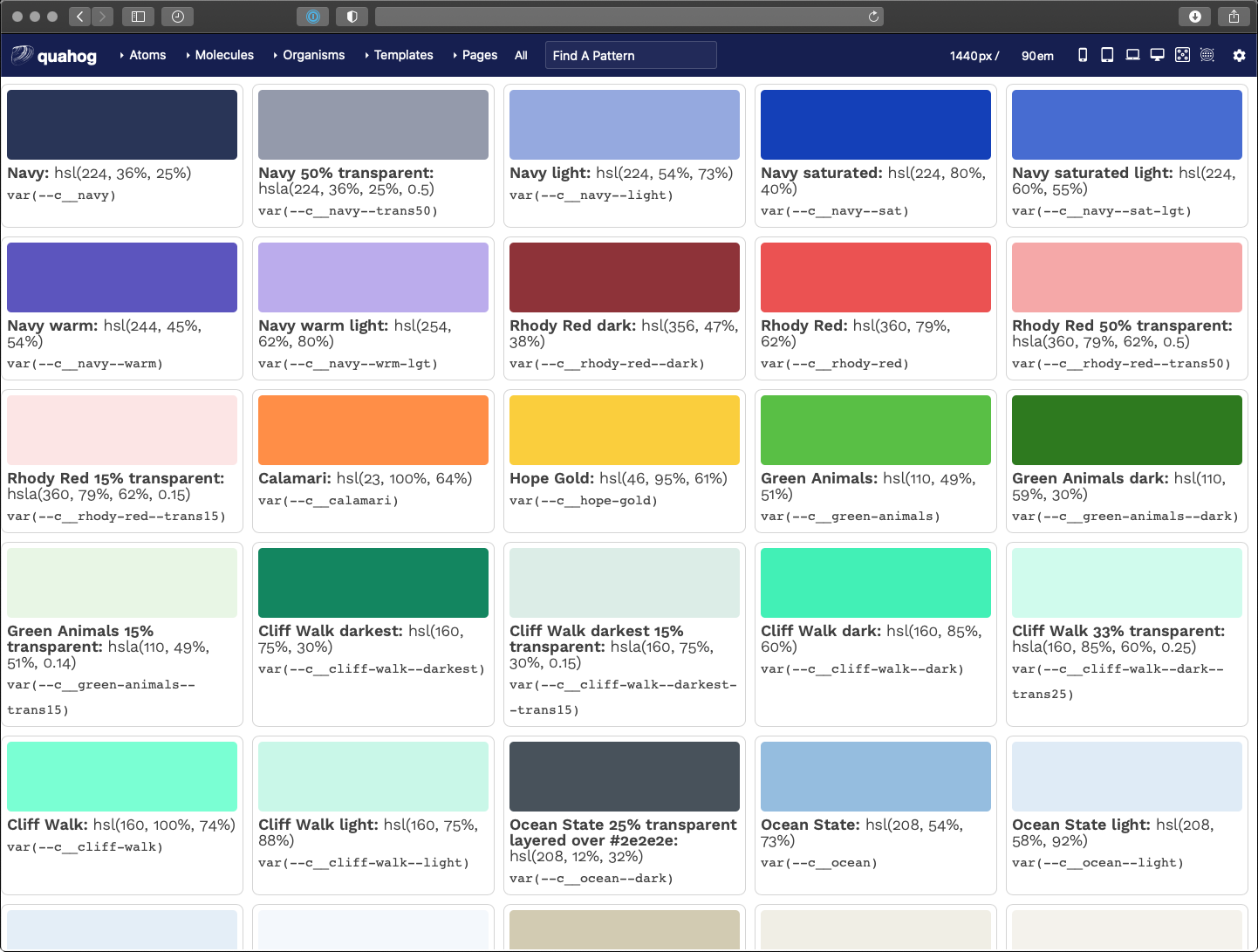
But that’s not all…
Theme Definitions
The second array in our HJSON file controls our themes — again, five different color themes each with a light- and dark-mode. To manage these effectively, we had to make some architectural decisions. Here is where we landed:
- Break the theme down into components, like “header”, “nav-main”, and “default” among others
- Name these theme colors with a functional component name — i.e., in the main navigation, a color name might be
var(--fc__nav-main__fg)which representsfunctional color, navigation main, foreground - Define functional colors in themes as a reference to the colors array
This structure allows a front-end developer to only concern themselves with the functional color name — i.e., --fc__nav-main__link. They don’t need to know what color that maps to as long as it has been defined in the theme. The theme designer is the one that focuses on making colors available and controlling the accessibility of those color combinations.
Define the Themes
Much like our color definitions, the top depth of the array defines our color theme
"palettes": {
"scarborough": {
"humanName": "Scarborough Beach",
"values": { … }
}
}
JSON
We only need a slug, which is the array key, and a humanName. The slug will be used to output a list of colors per theme. The human-readable name is used in a dynamically-generated list of available themes through the authoring admin screens (more to come on that later).
Define the Components
Inside the values array, each component definition is included. The list is long, but a sample of it looks like this (with our inline comments allowed by HJSON):
"header": [
{ "fnName": "fg", "colorName": "white" },
{ "fnName": "bg", "colorName": "navy" },
{ "fnName": "link", "colorName": "white" },
{ "fnName": "link--hover", "colorName": "ocean" },
{ "fnName": "social__link", "colorName": "ocean" },
# Hover should be the same as the default accent color
{ "fnName": "social__link--hover", "colorName": "hope-gold" }
]
JSON
These compile to a list of color definitions per component. The final color variables look like this:
html {
/* Default functional colors used by the header component */
--fc__header__fg: white;
--fc__header__bg: #293557;
--fc__header__link: white;
--fc__header__link--hover: #95bddf;
--fc__header__social__link: #95bddf;
--fc__header__social__link--hover: #face3d;
}
CSS
Output the theme components
Our themes are controlled by overriding the functional color definitions with specificity. A loop in our colors.scss file renders all the colors and all the themes as CSS variables. The first theme definition serves as our default, while additional definitions with a class present on the <body> override those definitions.
It makes more sense in CSS. Here is a full example of only the header component:
html {
/* Default functional colors used by the header component */
--fc__header__fg: white;
--fc__header__bg: #293557;
--fc__header__link: white;
--fc__header__link--hover: #95bddf;
--fc__header__social__link: #95bddf;
--fc__header__social__link--hover: #face3d;
}
/* Default colors for dark mode (overrides only) */
html.dark {
--fc__header__bg: #1b243b;
}
@media (prefers-color-scheme: dark) {
html:not(.light) {
--fc__header__bg: #1b243b;
}
}
/* Component colors when a theme class is present (overrides only) */
html .qh__t__federal-hill {
--fc__header__bg: #8e3339;
--fc__header__link--hover: #face3d;
--fc__header__social__link: white;
}
/* Component colors when a theme class is present AND it is dark mode (overrides only) */
html.dark .qh__t__federal-hill {
--fc__header__bg: rgba(235, 82, 82, 0.15);
--fc__header__social__link: #eb5252;
}
@media (prefers-color-scheme: dark) {
html:not(.light) .qh__t__federal-hill {
--fc__header__bg: rgba(235, 82, 82, 0.15);
--fc__header__social__link: #eb5252;
}
}
CSS
The power of CSS specificity helps us here. The top of the file is our fallback for any functional color in our default theme — they all need to be present here. Any additional definitions only need to change those colors. Anything in html.dark overrides the colors in html4. Anything in html .qh__t__federal-hill overrides colors in html with specific theme colors. And anything in html.dark .qh__t__federal-hill overrides colors in html .qh__t__federal-hill when dark mode is present.
Outputting Visual Theme Previews
Similar to the Twig for loop for color swatches, we created a loop in Pattern Lab that renders a visual swatch to represent a theme. I won’t go into all the code here, but the trick we used was to create stripes of color using an inline CSS linear-gradient(). The result looks like this:
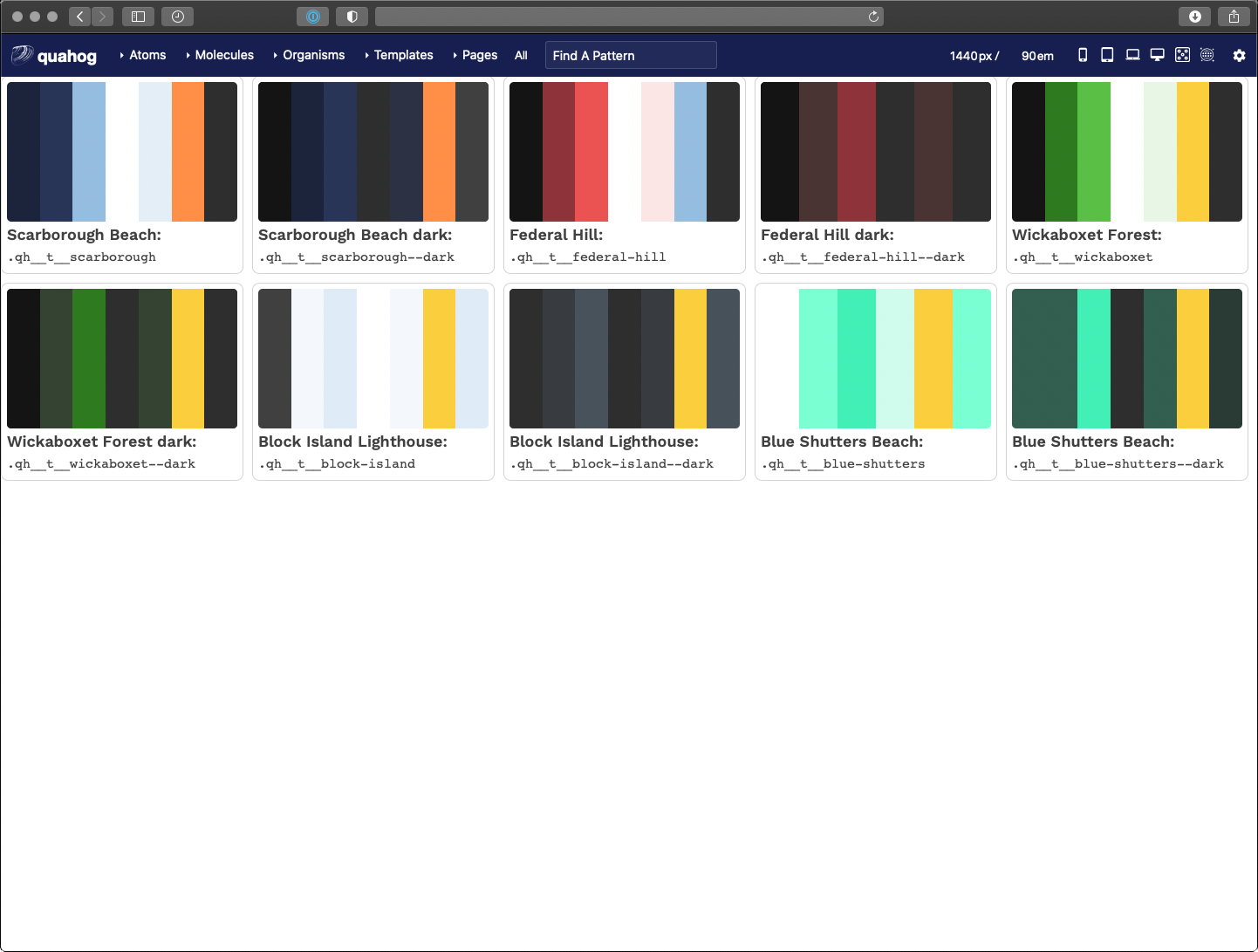
Taking it a Step Further for Accessibility
We decided that the theme designer would be responsible for providing accessible color contrast ratios (CCR) when defining --bg and --fg colors. It is up to them to choose which combinations to use, but with 46 colors, that’s 2,116 possible combinations! How can a theme designer know which combinations pass which CCRs?
Through the power of programming, we created another Twig file that leverages a nested for loop to create a large table. Across the top are our 46 colors and down the side are our 46 colors again. In the middle where a color row intersects a color column, we render enough data on the table cell to allow a Javascript loop to calculate the CCR for that combination of colors.
The result is a data table that shows every color combination and how that combination passes or does not conform to WCAG CCR thresholds. The power of for loops!
Here is what that looks like:
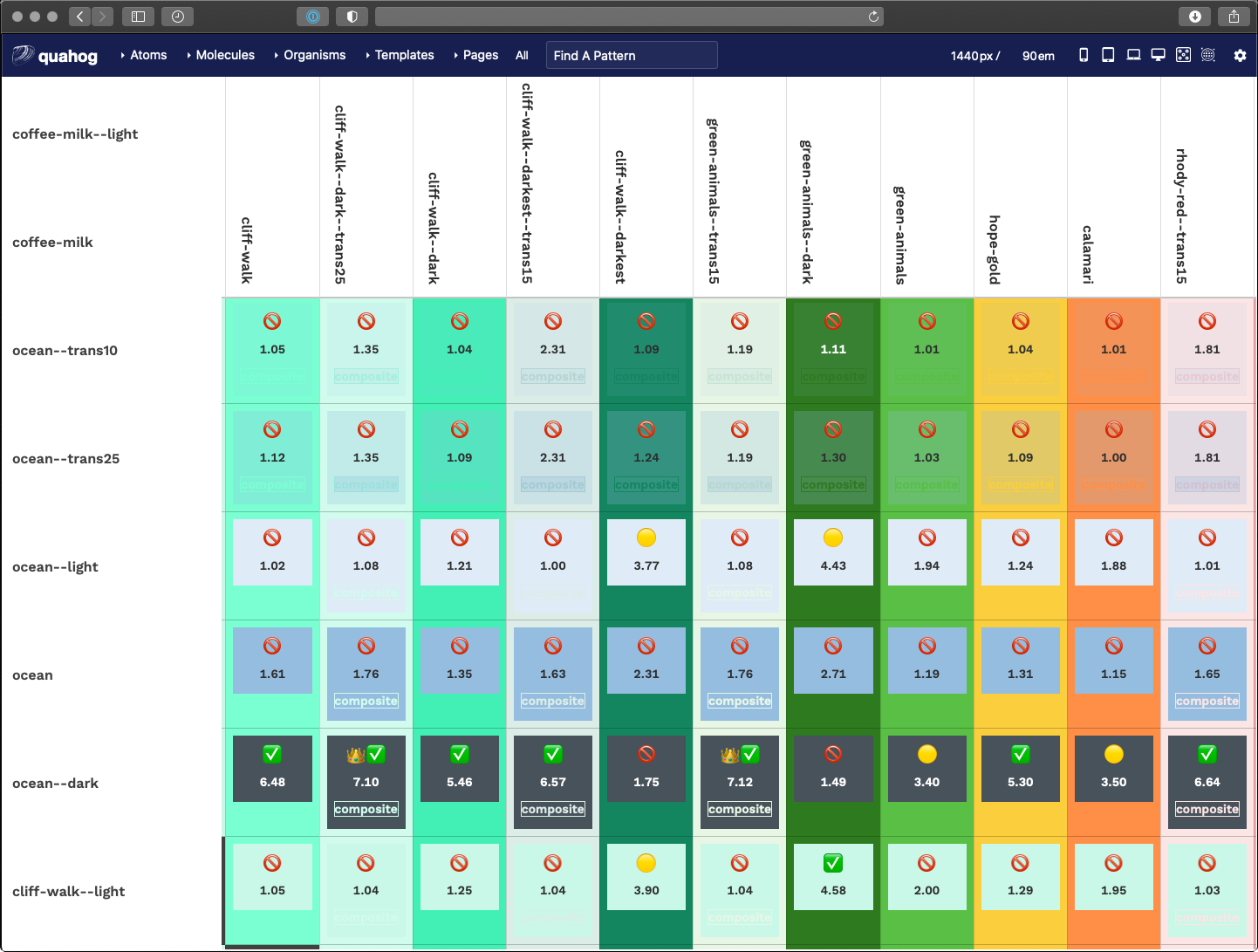
A fun little thing here is that we used emojis as our visual output. Anything under 3.0 is not allowed, anything 3.0 to 4.5 is passable under certain conditions, while anything over 4.5 is great and anything over 7.0 is royalty.
function setMessage(ccr) {
var message = '';
if (ccr >= 7.0) {
messge = '👑';
}
if (ccr >= 4.5) {
message = message + '✅';
}
if (ccr < 4.5 && ccr >= 3.0) {
message = '🟡';
}
if (ccr < 3.0) {
message = '🚫';
}
return message;
}
JavaScript
Another trick here was how to calculate CCR when one or more of the colors are transparent. In short, we had to do some JS that was aware of the background color — therefore, view this table in light mode AND dark mode to get the fullest amount of data around transparent color combinations.
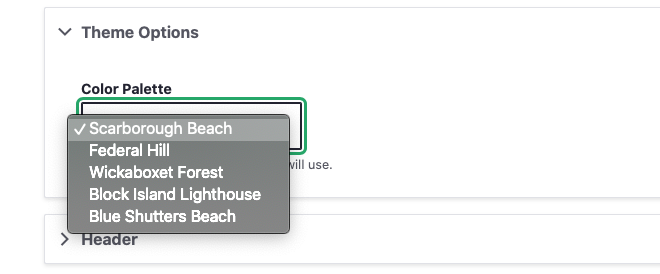
Displaying a Theme Selection
The final step of making our HJSON file control colors and themes from end to end is getting the list of themes into the admin of the site. With this, a site author can choose a color theme for their site, and further, when we add a new theme, that setting is available as soon as there is a new design system deployment.
A bit of PHP in the Drupal theme-settings.php file cycles through our JSON to render the select list of theme names. The end result of that looks like this:
Wrapping it all Up
In an extreme example of the DRY principle (Don’t Repeat Yourself), we’ve set up a system where one file rules all of our color definitions. A JSON array can render the following data through a Gulp process:
- Custom CSS properties for color definitions in Sass
- A Twig file with a visual preview of all colors
- Custom CSS properties for functional component colors within defined color themes for light and dark modes
- A Twig file with a visual preview of all themes
- A Twig file with a data table calculating color contrast ratios for all colors in the system, and
- A dynamic drop-down menu in the admin of the sites that allows a site author to choose a color theme
A HJSON to JSON/Sass/Twig/PHP workflow is certainly a great foundation. While this file manages only colors and themes, the same workflow could manage font-families, font-sizes, spacing values, and more. For now, we are taking it one step at a time but this certainly gives us some ideas to expand upon in the future.
- Yes, we could have added a comment field to our JSON structure, but we wanted more than that. Commenting individual lines with a hash character (“#”) was very helpful when we got to defining entire color themes
- Is this article actually about the new hotness, “design tokens”? Yes, in some ways, it is. Rather than being prescriptive about what and how to use design tokens, though, we concentrate on how we use them for this project. If you want to call them design tokens, that’s fine with us — but it’s not the main point.
- Why html and not
:root? Solely because the Javascript polyfill we use to support CSS variables with Internet Explorer 11 requires definitions on the HTML orbodyelement, and does not work if we use:root - Too bad about the media query for
prefers-color-schemeneeding to be declared in its own group. The repetition hurts a little bit but luckily the lists of colors are small.