
Bill Gates wrote “Content is King” back in 1996. He was right for about thirty years. On the open web, the winners were the ones who could produce, distribute, and monetize content at scale. That era shaped how we built digital products, how we organized marketing teams, and how we thought about content platforms.
That era is getting a new chapter.
When content becomes context
In the age of agents, content is context. It’s the raw material an AI uses to answer a customer’s question, draft a proposal, summarize a policy, or make a decision on behalf of your business.
If your context is a mess, your agent is a mess. Garbage in, confident-sounding garbage out.
For organizations in healthcare, higher education, and associations (industries where we work every day) that governance layer isn’t a nice-to-have. A health system deploying an agent to answer patient questions needs to know which clinical protocol is current, who approved it, and what the agent is and isn’t allowed to cite. An association managing member benefits can’t afford an agent that surfaces a two-year-old policy document as current guidance. And it’s not just the regulated organizations themselves. The enterprise technology companies that serve these industries, the SaaS platforms, the data providers, the system integrators, face the same challenge: if the content powering their products isn’t structured and governed, the agents built on top of it will inherit every gap. The stakes in regulated industries make the content-as-context problem concrete and urgent, but the same dynamics show up everywhere brand, voice, and accuracy matter: retail pricing, financial disclosures, B2B product specifications, public sector policy. Different risk profiles, same fundamental problem.
This isn’t theoretical. Gartner predicts that 40% of enterprise applications will include task-specific AI agents by the end of 2026, up from less than 5% in 2025. The shift is already moving from prediction to product.
The platforms we work with every day show the movement clearly. The Drupal AI Initiative launched last June and hit $1 million in funding within five months, with the Drupal AI and AI Agents modules reaching production-ready status in October 2025. Acquia built on that foundation with Acquia Source, shipping three AI agents for its Drupal-powered SaaS CMS in December. Contentful open-sourced its MCP server and has been publishing active guidance on agentic content operations. These aren’t experiments. They’re shipping.
Across the category, the pattern is broad. Contentstack launched Agent OS in September 2025 and introduced what it calls the “Context Economy” as its positioning. Kontent.ai shipped what it calls an Agentic CMS the following month. The Model Context Protocol that Anthropic introduced in late 2024 has become the connective tissue, adopted by OpenAI, Google DeepMind, and most of the CMS world.
The platforms are ready. The question is whether your content is.
What agents actually need
An agent doesn’t want a rendered web page. It wants structured, canonical, permissioned, versioned truth. That means:
- Structure so the agent can reason over content rather than scrape through marketing copy
- Versioning so it knows which policy, price, or product spec is current
- Permissions so the agent answering a customer question can’t pull from an internal-only HR doc
- Freshness signals so stale content doesn’t get treated as authoritative
- Governance so legal, brand, and compliance can trust what the agent says on their behalf
That’s the same job a mature content platform has been doing for years, just pointed at a new kind of consumer.
We’ve seen this movie before
Every channel shift exposes whether your content was ever really structured to begin with. CD-ROM, then the web, then mobile, now agents. Each one forces organizations to untangle content from presentation. Headless CMS platforms like Drupal, Contentful, Sanity, and Strapi won that argument. Content as structured data, delivered via API, rendered wherever you need it.
Agents are the most demanding channel yet. They don’t just display your content. They consume it, reason over it, and then take action. If your content is trapped inside HTML blobs or buried in PDFs that no one’s touched since 2021, it’s not ready to be context. Structure is the whole game now.
Where context lives today
Right now, company context is scattered across:
- Websites and headless CMS platforms
- GitHub repos full of markdown
- Confluence, Notion, SharePoint, Google Drive
- Salesforce, HubSpot, and a dozen other systems of record
- PDFs, Slack threads, and somebody’s laptop
Some of these are built for governance. Most aren’t. GitHub is hands-down great for technical content and version control, but marketing and legal teams aren’t opening pull requests to update a pricing page. Notion is excellent for collaboration, weak on structured content models and role-based delivery. Every organization I talk to has some version of this scatter, and it’s about to become a much bigger problem.
The rise of the Context Management System
The old acronym still works. CMS. New job.
Headless CMS platforms have quietly solved about 70% of what agents need. Structured content models. API-first delivery. Editorial workflows. Roles and permissions. Versioning. Audit trails. What they’re adding now is the connective tissue. Acquia is embedding AI agents directly into Drupal-powered workflows through Acquia Source, and Contentful has open-sourced its MCP server to let agents take action on content operations. Across the rest of the category, Sanity launched its Content Agent in January 2026, and Storyblok, Brightspot, and dotCMS have released MCP servers of their own. MCP servers, vector indexing, semantic metadata, agent-optimized delivery endpoints. That’s a much smaller leap than building the whole governance layer from scratch.
The “just throw it all in a vector database” approach has real merit as a retrieval layer. Retrieval is one job. Governance is a different one: who owns canonical truth, who approved the content, when it expires, and who’s allowed to see it. That’s always been the CMS job. It matters more now, not less.
For teams working on Drupal, Contentful, or Acquia Source, this is encouraging. The architectural decisions those platforms made years ago (structured data, granular revisioning, API-first design) turn out to be exactly what AI agents need. Your investment in content architecture is paying off in ways you didn’t plan for. Call it a head start.
What to do about it
If you’re building agentic products, or planning to, the content question is the quiet one that will bite you later. This is the work we’re spending most of our time on with clients right now. A few forward moves:
- Audit where your content actually lives and who owns it. You will be surprised.
- Pick a source of truth for each category of content. Don’t let five systems claim the same ground.
- Get your structured content models right. If your content is trapped inside HTML, it isn’t ready to be context.
- Build the governance layer before you need it. Versioning, permissions, approval workflows. Your legal team will thank you. So will your agent.
- Connect your CMS to your agents via MCP or equivalent. This is how context flows. Do it early.
Content was king when the battle was for attention. Context is king now that the battle is for correctness. Agents are only as good as the material you feed them, and that material has to be managed with the same rigor we’ve applied to code, to data, and yes, to content itself.
The organizations that treat content governance as infrastructure, not a cleanup project, will be the ones whose agents are trustworthy from day one. That window is shorter than it looks.
Summary
Most organizations are treating SEO and Generative Engine Optimization as two separate disciplines – and wasting resources in the process. The real strategic question is not which channel to optimize for but whether your content is built to be reused: extracted, synthesized, and cited by both search algorithms and AI answer engines. We call this Citation-Ready Content Architecture – a unified approach where structure, authority, and specificity make content perform across every discovery surface simultaneously. Organizations in regulated industries face compressed timelines: healthcare queries already trigger AI Overviews on nearly half of all searches.
Sixty percent of Google searches now end without a click. That number is not a forecast – it is a 2025 finding from Bain & Company. Meanwhile, Gartner predicts traditional search volume will drop 25% by the end of 2026 as users migrate to AI-powered answer engines. And here is the statistic that should change how you think about your content strategy: according to Ahrefs, 80% of URLs cited by ChatGPT, Perplexity, and Copilot do not rank in Google’s top 100 results for the original query.
That last data point is the one most SEO-vs.-GEO articles ignore. If the overlap between traditional rankings and AI citations were nearly complete, you could optimize for one and trust the other to follow. It is not. The two discovery channels draw from overlapping but meaningfully different content signals. Treating them as a single problem or two separate problems are both the wrong framing.
Why Is the “SEO vs. GEO” Framing Wrong?
Because it implies a choice between two competing strategies, when what actually matters is a single architectural principle applied across both.
SEO optimizes content for ranking position – getting your page onto a results list a human scans and clicks. GEO – Generative Engine Optimization, a term formalized by researchers at Princeton, Georgia Tech, and IIT Delhi in 2024 – optimizes content so AI systems can retrieve, synthesize, and cite it when generating answers. The Princeton study demonstrated that GEO techniques can boost content visibility in AI-generated responses by up to 40%, and that the most effective strategies vary by domain.
The difference is real. But the industry conversation has overcorrected, treating GEO as something exotic that requires a fundamentally new playbook. As Entrepreneur reported in April 2026, teams are making preventable mistakes by treating GEO “like an exotic new discipline” and shifting budget away from technical SEO into untested “AI visibility hacks.” Research from AirOps found that pages ranking number one in Google were cited by ChatGPT 3.5 times more often than pages outside the top 20.
Strong SEO remains the foundation. GEO is the structural extension that makes your existing authority legible to AI systems. They are not two strategies. They are one architecture.
What Makes Content “Citation-Ready” for Both Search and AI?
Citation-Ready Content Architecture is the practice of structuring content so it simultaneously ranks in traditional search results and gets extracted and cited by AI answer engines. It is not a new technology stack or a separate editorial workflow. It is a design principle: every piece of content your organization publishes should be built for reuse from the start.
Three characteristics define citation-ready content:
Modular structure. AI systems do not read your article top to bottom and decide whether to cite the whole thing. They extract passages – a definition, a statistic, a direct answer to a question. Content with clear headings, self-contained sections, and answer-first paragraphs gives both search engines and AI systems clean material to work with. The Princeton GEO study found that adding statistics to content improved AI visibility by 41%, and citing credible sources improved it by 115% for lower-ranked pages.
Demonstrated authority. Seer Interactive’s September 2025 study of 3,119 queries across 42 organizations found that brands cited in AI Overviews earned 35% more organic clicks and 91% more paid clicks than those not cited. Authority is no longer just a ranking signal – it is the qualification for being included in AI-generated answers at all. Author credentials, original research, linked sources, and topical depth are now dual-purpose investments.
Specificity over generality. AI systems select content that provides extractable facts – numbers, definitions, named frameworks, concrete comparisons. Content that gestures vaguely at a topic (“there are many factors to consider”) gets skipped in favor of content that states something specific and citable. We have written previously about how LLMs index and use content – the same accessibility and structural principles that help AI crawlers parse your pages also make your content more citation-worthy.
Why Are Healthcare and Higher Education Hit Hardest?
Because AI Overviews appear at disproportionately high rates for the query types these industries depend on – and the consequences of being absent or misrepresented are far more serious than lost traffic.
Conductor’s Q1 2026 analysis of 21.9 million searches found that healthcare queries trigger AI Overviews at a rate of 48.75% – nearly double the overall average of 25%. Technology queries trigger at roughly 30%. For healthcare organizations and universities, AI is already mediating nearly half the informational queries that drive patient acquisition and enrollment.
The real-world impact is already measurable. U.S. News reported in March 2026 that nearly 80% of people searching for degree information read Google’s AI Overviews, and many never click through to an institution’s website. The University of Maryland Global Campus responded by using AEO and GEO techniques to revise its degree pages and A/B test FAQ-style content. Johnson County Community College found that while AI-driven traffic represents less than 1% of its website visitors, engagement from that group is 59% above its site-wide average – suggesting AI-referred visitors arrive further along in their decision-making process.
For healthcare, the stakes go beyond enrollment. When AI engines synthesize clinical information, the accuracy of that synthesis depends on the quality and structure of the sources available. Organizations that have not optimized their content for AI citation are not just losing visibility – they are ceding authority over how their expertise gets represented to patients who increasingly trust AI-generated answers.
What Does the HubSpot Collapse Tell Us About This Shift?
That traffic built on loosely related content is structurally fragile in an AI-mediated search environment.
Multiple industry analyses documented an approximately 80% traffic drop across HubSpot’s blog properties as AI Overviews began answering the high-funnel informational queries that had driven HubSpot’s organic growth for over a decade. Pages about “famous sales quotes” and “cover letter examples” had driven enormous traffic but had minimal connection to HubSpot’s core CRM platform. When Google’s algorithm update prioritized content closely tied to a website’s core expertise, and AI Overviews began answering those generic queries directly, the traffic evaporated.
The lesson is not that content marketing failed. It is that content disconnected from your organization’s core authority is exactly the kind of content AI systems will summarize without ever sending a visitor your way. In our GEO optimization Q&A, we outline why organizations should start with their highest-authority content when optimizing for AI visibility rather than trying to cover every possible keyword.
For organizations in regulated industries – where your content is tightly tied to your institutional expertise by design – this is actually an advantage. A hospital publishing evidence-based patient education content is inherently closer to citation-ready than a SaaS company publishing tangentially related blog posts for traffic volume. The structural alignment is already there. What is often missing is the formatting and schema work that makes it extractable.
What Should Content Teams Do First?
Start with what you already have. The gap between SEO-optimized content and citation-ready content is usually structural, not substantive.
1. Audit your top 20 pages for extractability. Read the first paragraph of each section in isolation. Does it directly answer a question someone would ask an AI tool? If not, restructure it. AI systems and Google’s AI Overviews pull from the opening sentences of well-structured sections – bury your answer three paragraphs deep and it will not get cited.
2. Add the schema AI systems actually use. Implement FAQPage, Organization, Article, and author schema across your priority content. BrightEdge found that sites implementing structured data and FAQ blocks saw a 44% increase in AI search citations. Author schema is especially high-impact: websites with author schema are 3x more likely to appear in AI answers.
3. Track AI visibility alongside traditional rankings. Oomph’s GEO Analytics and Reporting service configures tracking in GA4 and Google Search Console to monitor AI bot traffic and AI-generated search impressions that standard analytics miss. At minimum, create referral segments for chat.openai.com, perplexity.ai, and other AI platforms, and watch for the signature pattern of rising impressions with declining clicks – the clearest signal that AI is summarizing your content without sending traffic.
The organizations that will maintain visibility over the next two years are not the ones choosing between SEO and GEO. They are the ones building content that works across both discovery surfaces from the start – structured for extraction, grounded in genuine expertise, and specific enough that AI systems treat it as source material rather than background noise.
That is not a new content strategy. It is the old one, built to the standard the new environment actually requires.
Summary
Most content strategies optimize for one outcome: ranking. Ranking is only half the visibility equation now. Citation-Ready Content Architecture, developed at Oomph, helps organizations build content that performs across traditional search results and AI-generated answers simultaneously. It rests on three principles – modular structure, demonstrated authority, and extractable specificity – and we apply it with clients in healthcare, higher education, and government where being cited accurately is as important as being found.
This crystallized during a client conversation earlier this year. We were looking at their analytics – a major healthcare organization – and the pattern was striking. Impressions were climbing. Rankings were stable. But clicks were dropping steadily, month over month. The content was being surfaced by Google, but patients were getting their answers from AI Overviews without ever visiting the site.
That’s a visibility problem most of us weren’t trained to solve – and it requires a different content architecture.
Gartner predicts traditional search volume will drop 25% by the end of 2026 as users migrate to AI-powered answer engines. Ahrefs found that 80% of URLs cited by ChatGPT, Perplexity, and Copilot don’t rank in Google’s top 100 for the original query. And the Pew Research Center’s study of 68,879 actual Google searches found that only 8% of users clicked a traditional result when an AI Overview appeared, compared to 15% without one – roughly half the click-through rate.
Content that ranks and content that gets cited aren’t always the same – but they can be, if you build for both from the start. That’s Citation-Ready Content Architecture.
What Is Citation-Ready Content Architecture?
Citation-Ready Content Architecture is the practice of structuring digital content so it simultaneously ranks in traditional search engine results and gets extracted, synthesized, and cited by AI answer engines like ChatGPT, Google AI Overviews, and Perplexity. Developed by Oomph as a framework for regulated industries, it combines modular content structure, demonstrated authority signals, and extractable specificity into a unified content design principle – replacing the need to maintain separate SEO and GEO strategies.
The key word in that definition is “simultaneously.” That means content architecturally designed to work across every discovery surface – ranked results, AI summaries, voice assistants, whatever comes next – because the underlying structure supports all of them.
In our work with clients across healthcare, higher education, and government, we’ve found this transition isn’t a massive lift for organizations with strong content fundamentals. The gap between SEO-optimized and citation-ready content is structural, not substantive – it’s about how content is organized, not whether it’s good.
Why Do Organizations Need a New Content Architecture Now?
Information discovery has forked. Content built for only one path leaves visibility on the table.
Two parallel discovery systems now exist. Traditional search ranks your content in a list users scan. AI-powered answer engines synthesize information from multiple sources into a single response – often without the user ever clicking through to your site.
The research is unambiguous. The foundational Princeton GEO study demonstrated that content optimized for generative engines can boost visibility by up to 40% in AI responses. But it also showed that the most effective strategies vary by domain – what works for a law firm doesn’t necessarily work for a children’s hospital. A March 2026 study from researchers at the University of Tokyo found that structural optimization alone – independent of content changes – improved citation rates by 17.3% across six major generative engines.
The most striking finding: research from AirOps found that pages ranking number one in Google were cited by ChatGPT 3.5 times more often than pages outside the top 20. Strong SEO remains the foundation. Citation-ready architecture is what makes that foundation legible to AI systems too.
What Are the Three Principles of Citation-Ready Content?
The framework rests on three principles. Each serves both search engines and AI systems simultaneously – that dual purpose is the point.
Modular structure
AI systems don’t read your article start to finish and decide whether to cite the whole thing. They extract passages – a definition, a data point, a direct answer to a specific question. Content with clear headings, self-contained sections, and answer-first paragraphs gives both search algorithms and AI systems clean material to work with.
We’ve written about how LLMs index and use content – and the takeaway is that the same accessibility principles that help AI crawlers parse your pages also make your content more citation-worthy. Semantic HTML, logical heading hierarchies, and sections that can stand on their own aren’t new concepts. They’re just worth more now than they’ve ever been.
Demonstrated authority
Being cited by AI systems has become a meaningful competitive advantage. BrightEdge found that sites earning citations inside AI Overviews see CTR increases of up to 35% compared to traditional organic rankings alone. Websites with author schema are 3x more likely to appear in AI answers, and sites implementing structured data and FAQ blocks saw a 44% increase in AI search citations.
In practice, demonstrated authority means: Author credentials on every piece. Original data and research when you have it. Linked sources for every claim. Topical depth across related content – not one-off articles, but interconnected clusters that demonstrate sustained expertise.
Authority isn’t just a ranking signal – it’s the entry qualification for AI inclusion.
Extractable specificity
This is the one that separates citation-ready content from content that’s merely well-written. AI systems select content that provides extractable facts – numbers, definitions, named frameworks, concrete comparisons. Content that gestures at a topic (“there are many factors to consider”) gets skipped in favor of content that states something specific and citable.
The Princeton study found that adding statistics to content improved AI visibility by 41%, and citing credible sources improved visibility by 115% for lower-ranked pages. That 115% figure is significant: it means content that isn’t winning the traditional ranking game can still earn AI citations by being specific and well-sourced.
How Does This Apply Differently in Regulated Industries?
For regulated industries, the stakes are higher and the timeline compressed – but the structural fit is actually better.
Conductor’s Q1 2026 analysis of 21.9 million searches found that healthcare queries trigger AI Overviews at a rate of 48.75% – nearly double the overall average. For healthcare organizations and universities, AI is already mediating close to half the informational queries that drive patient acquisition and enrollment.
The structural advantage for regulated industries is real. Organizations in regulated industries – healthcare systems, universities, government agencies – produce content that’s inherently tied to their institutional expertise. A hospital publishing evidence-based patient education content is structurally closer to citation-ready than a SaaS company publishing tangentially related blog posts for keyword volume. The authority is real. The specificity is built in by the nature of the content. What’s typically missing is the formatting and schema work that makes it extractable.
When we optimize content for GEO, the biggest wins often come from restructuring content that already exists – not creating new content from scratch.
What Should You Do First to Make Your Content Citation-Ready?
Start with what you have. The gap is almost always structural, not substantive.
- Audit your top 20 pages for extractability. Read the first paragraph of each section in isolation. Does it directly answer a question someone would ask an AI tool? If it doesn’t, restructure it. AI systems pull from the opening sentences of well-structured sections. Bury your answer three paragraphs in and it won’t get cited.
- Implement the schema that AI systems actually use. FAQPage, Organization, Article, and author schema across your priority content. Author schema is especially high-impact – BrightEdge’s research shows it triples your likelihood of appearing in AI answers.
- Track AI visibility alongside traditional rankings. Oomph’s GEO Analytics and Reporting service configures tracking in GA4 and Google Search Console to monitor AI bot traffic and AI-generated search impressions. At minimum, watch for the pattern of rising impressions with declining clicks – that’s the clearest signal that AI is summarizing your content without sending visitors.
- Build for reuse from the start. Every new piece of content should include at least one standalone definition, one specific data point, and one direct answer to a question your audience would ask an AI tool. Make it easy for AI systems to cite you. That’s the architecture.
In 20 years of building digital experiences, I’ve watched a handful of shifts fundamentally change how content needs to be structured. Mobile was one. Accessibility-first was another. The shift to AI-mediated discovery is the next.
Citation-Ready Content Architecture isn’t a bolt-on to your existing strategy – it’s the design principle that makes your existing strategy work across today’s fragmented discovery environment. Organizations that build for it now will compound that advantage as AI-mediated search grows. Those that wait will be optimizing for a world that has already moved on.
We’re helping clients across healthcare, higher education, and government make this shift. If your analytics show that pattern – impressions climbing, clicks dropping – start here.
Contentful is no longer just an alternative CMS—it’s become a foundational platform for organizations navigating complexity, regulation, and rapid digital change. In 2026, the question isn’t what is Contentful? It’s why are so many organizations rebuilding their digital ecosystems around it? The answer lies in how digital experiences are built, managed, and scaled today.
Contentful Is Built for Systems, Not Pages
Traditional CMS platforms were designed around pages and templates. That model breaks down when content needs to move faster, live in more places, and remain consistent across teams and channels.
Contentful takes a different approach. It treats content as structured data, not static pages. That means teams create content once and deliver it anywhere—websites, apps, portals, email, or future channels that don’t yet exist.
In 2026, this isn’t a “nice to have.” It’s how modern digital platforms operate.
Composable Architecture Is Now the Default
Composable architecture has moved from trend to standard. Organizations want the freedom to choose best-in-class tools without being locked into monolithic platforms.
Contentful fits cleanly into this model. It integrates with design systems, analytics platforms, personalization tools, consent managers, and AI services through APIs—without forcing teams into rigid workflows.
This flexibility allows organizations to evolve their stack over time instead of rebuilding every few years.
AI Depends on Structured Content
AI-driven experiences are only as good as the content behind them. In 2026, organizations are using AI to support personalization, search, localization, content optimization, and automation.
Contentful’s structured content model makes this possible. Clean, well-defined content enables AI tools to understand, reuse, and adapt content accurately—without introducing risk or inconsistency.
For teams exploring AI responsibly, Contentful provides the infrastructure needed to scale with confidence.
Governance and Compliance Are Built In, Not Bolted On
For regulated and mission-driven organizations, governance isn’t optional. Publishing controls, audit trails, permissions, and review workflows are essential.
Contentful supports these needs at scale. Teams can define roles, control who edits or publishes content, and maintain visibility into changes across environments. This level of governance is critical in industries like healthcare, legal, finance, and the public sector.
In 2026, compliance isn’t something teams add later—it’s designed into the platform from day one.
Marketing and Development Work Better Together
One of Contentful’s biggest advantages is how it aligns marketing and engineering teams. Developers maintain design systems and integrations. Content teams manage content without breaking layouts or workflows.
This separation of concerns reduces friction, speeds up delivery, and minimizes production errors—especially as digital ecosystems grow more complex.
Ready to explore what Contentful could do for your organization? Whether you’re evaluating platforms, planning a migration, or looking to optimize your current setup, Oomph can help you build a content infrastructure designed for the long term. Let’s talk about your next move.

Why Organizations Move to Contentful Now
Organizations typically migrate to Contentful when legacy systems start holding them back. Common triggers include:
- Slow publishing workflows
- Heavy developer dependency
- Difficulty scaling across channels
- Growing compliance requirements
- The need to support AI and personalization
In 2026, Contentful isn’t chosen because it’s new. It’s chosen because it’s resilient.
For organizations new to the platform, getting started doesn’t have to mean a complete rebuild. Oomph’s Contentful Kickstart Package helps teams move from decision to deployment with a structured, low-risk approach—giving you the foundation to scale as your needs evolve.
The Takeaway
Contentful has evolved alongside the modern digital landscape. It’s not just a CMS—it’s a content platform designed for scale, governance, and change.
For organizations planning beyond their next website launch and toward long-term digital maturity, Contentful provides the flexibility and confidence needed to move forward.
Ready to explore what Contentful could do for your organization? Whether you’re evaluating platforms, planning a migration, or looking to optimize your current setup, Oomph can help you build a content infrastructure designed for the long term. Let’s talk about your next move.
In recent months, Generative Engine Optimization (GEO) has been gaining attention, often positioned as the next evolution beyond traditional Search Engine Optimization (SEO). For some clients, this presents an exciting opportunity to rethink and restructure their digital content. For others, it can feel overwhelming, raising more questions than answers. As AI-powered search tools like ChatGPT, Perplexity, and Gemini change how people discover content online, clients increasingly ask: What is GEO, and how can we prepare our sites for it?
The following handy Q&A guide aims to demystify Generative Engine Optimization (GEO), explain why it matters, and provide practical steps your team can take to get started.
Q: What is GEO and how is it different from SEO?
A: GEO stands for Generative Engine Optimization. While SEO (Search Engine Optimization) focuses on getting your content to rank in traditional search engines like Google (via keywords, backlinks, and site performance), GEO focuses on getting your content mentioned, referenced, summarized, or cited in AI-generated answers from tools like ChatGPT, Gemini, and Perplexity.
Think of SEO as getting your content listed, whereas GEO is about making your brand and its content the answer.
Q: Why should my organization care about GEO?
A: AI platforms are rapidly becoming the first stop for users looking for answers, especially younger audiences and professionals. If an answer appears via Gemini on the top of a Google search, fewer people may scroll further down the page to look for other sources. They got the answer they needed from just one search. If your content isn’t optimized for these tools, you’re missing out on certain traffic data, visibility, and an opportunity to build trust.
In 2026, ChatGPT alone sees over 4.5 billion visits per month, and Perplexity handles nearly 500 million monthly queries.
Q: How is GEO impacting my site’s analytics?
A: Likely a lot. Generative engines often summarize content without requiring a click. That means you may see fewer impressions and clicks, even if your content is powering the AI’s answer. Most websites are seeing direct traffic declining across the board. With that said, users who do click through to sites are often engaging more deeply, leading to longer session durations and higher conversion rates.
Because of this, it’s crucial to learn these new patterns and recognize them within your site’s analytics by setting up new reports.
Q: How do AI engines choose which content to cite?
A: AI tools evaluate a number of factors, with the most important being:
- Authority: Are you a trusted source? Do you have backlinks, credentials, or media citations?
- Structure: Do you use schema markup, headings, and clear Q&A formatting?
- Freshness: Is your content updated regularly?
- Relevance: Does your content align with how users ask questions in natural language?
Each tool has its own algorithm, but clear, factual, structured content with recent updates from trusted sources performs best.
Q: What kind of content works best for GEO?
A: Content that answers questions directly, especially with a conversational tone, tends to work well. Additionally, you want your content to explain not just the what, but also the why and how, since generative engines often expand on user intent. Content structures that perform well for GEO include:
- Q&A sections
- “Top” or “Best” lists (Examples: Top Restaurants in Providence, Rhode Island or Best fall events in California)
- Evergreen guides that are updated annually
- Content that is organized for machines and humans (aka clear headings, mobile-friendly, structured data and metadata)
Q: How can we tell if our content is being featured in AI tools?
A: While most AI platforms don’t yet provide native analytics, you can track GEO success through:
- GA4 segmentation: Filter referral traffic by sources like chat.openai.com or perplexity.ai
- Landing page patterns: AI-driven referrals often land users deep into your site (e.g., specific blogs, not just the homepage)
- Google Search Console: Look for queries with high impressions but low click-through rates, these may indicate your content is being shown in AI Overviews
- Manual Testing: In an incognito window, search for the types of queries you want your site’s content to appear for and see what answers are returned. These might be simple questions like “What does [your organization] do?” or more in-depth research questions that your popular articles have addressed.
- Third Party Tools: As the field continues to develop, more third party tools are becoming available or adapting their analytics to provide insight into GEO success. SEMrush in particular is a tool that we recommend for clients interested in uncovering more data.
Q: Is there a way to make our site more “AI-friendly”?
A: Yes! Here are key GEO best practices:
- Use schema markup: Help AI models understand your content’s structure and intent. You can use schema.org to help guide you through improving your site’s markup.
- Write in a Q&A or conversational format: More people are asking full questions or prompts in ChatGPT—rather than just listing keywords. Match your content with how users phrase queries in AI tools.
- Optimize your About page: Make sure that your About page is thoughtfully written to answer who you are, what you do, and why. ChatGPT, for example, pulls from these pages to assess trustworthiness and authority.
- Refresh content: Update existing articles with new data and a clear structure (aka headings, bullets, FAQ sections, summaries). Note: You don’t need to create new URLs, just refresh the content to make sure it is relevant and current for today.
- Include citations and data points: Wherever possible, add data and sources. These increase your authority and credibility.
Q: Do we need to optimize differently for each AI tool?
A: The core strategies (trustworthiness, schema, natural language, performant) apply across all platforms, but there are nuances:
- Gemini: Heavily tied to Google’s ecosystem. Focus on crawlability and Core Web Vitals.
- Perplexity: Prefers cited, factual content and uses real-time web data.
- ChatGPT: Draws from authoritative sources like Wikipedia, news outlets, and Reddit. Strong personalization and structured content help here.
Q: Can we block AI tools from using our content?
A: Yes, but be thoughtful about what you are blocking. Adding a file like robots.txt can block AI crawlers, but doing so may reduce your visibility and lead to attribution from AI tools. It could also block legitimate crawlers and thus negatively impact both SEO and GEO, so be thoughtful about how you compose and format that file.
Note: If your brand has legal or content ownership concerns, we can help you assess what should or shouldn’t be available for AI training or citation.
Q: Do AI Tools honor authenticated access?
A: Yes, but remain mindful. Models like ChatGPT can’t “log in” or bypass authentication. If full research content is only available behind a user login, it won’t be included in training data or scraped summaries. But still pay attention to how content is displayed. If your research is behind a login or subscription paywall, ensure that:
- No full-text content is available to crawlers
- Abstracts or summaries shown publicly are limited in detail
Q: What is llms.txt and should I add it to my site?
A: llms.txt is a proposed convention for websites to provide a lightweight, machine- & human-readable summary (in Markdown) of the “important” parts of the site, to help large language models (LLMs) more easily crawl, interpret, and use content. More sites are starting to add it to their sites to help guide which pages AI should pay attention to. However, it is not yet a universally supported or enforced standard. Many LLMs or AI platforms do not currently yet automatically look for or honor llms.txt. As of now, you can think of it as a nice-to-have, not a requirement.
Q: How often should we update content for GEO?
A: Best practice recommends updating at least once a year for evergreen content. Prioritize updates for:
- Posts using phrases like “top,” “best,” or “recommended”
- Pages that receive seasonal traffic or include stats
- Key content that’s losing impressions or traffic in Google Search Console
Even simple updates like reordering information, adding new facts, or improving layout can go a long way with AI engines.
Q: Is GEO just another passing trend?
A: Not at all. GEO is a direct response to how AI is changing digital search and content discovery. Platforms like Google are rethinking their search experience through tools like Gemini, as more people turn to these tools for answers. GEO is how brands stay visible in this new AI landscape.
Q: What’s the first step we should take for GEO Optimization?
A: Start with a content and schema audit of your top-performing pages. From there, apply structured markup, rewrite headlines for clarity, add Q&A sections where applicable, and refresh key posts. A phased approach focused on high-value content will have the biggest immediate impact.
Need help figuring out what content to prioritize for GEO? Our team at Oomph can assess your current visibility and build a roadmap tailored to AI performance.
For more insights into GEO optimization, read…
- Everything You Should Know About Optimizing for GEO in 2026
- How LLMs Index Your Site — and How Accessibility Improves Their Answers and Your GEO
Generative Engine Optimization (GEO) is making organizations scramble — our clients have been asking “Are we ready for the new ways LLMs crawl, index, and return content to users? Does our site support evolving GEO best practices? What can we do to boost results and citations?”
Large language models (LLMs) and the services that power AI summaries don’t “think” like humans but they do perform similar actions. They seek content, split it into memorable chunks, and rank the chunks for trust and accuracy. If pages use semantic HTML, include facts and cite sources, and include structured metadata, AI crawlers and retrieval systems will find, store, and reproduce content accurately. That improves your chance of being cited correctly in AI overviews.
While GEO has disrupted the way people use search engines, the fundamentals of SEO and digital accessibility continue to be strong indicators of content performance in LLM search results. Making content understandable, usable, and memorable for humans also has benefits for LLMs and GEO.
How LLM systems (and AI-driven overviews) get their facts
Understanding how LLMs crawl, process, and retrieve web content helps us understand why semantic structure and accessibility best practices have a positive effect. When an AI system generates an answer that cites the web, several distinct back-end steps usually happen:
- Crawling — Bots visit URLs and download page content. Some crawlers execute javascript like a browser (Googlebot) while others prefer raw HTML and limit their rendering.
- Chunking — Large documents are split into small, logical “chunks” of paragraphs, sections, or other units. These chunks are the pieces that are later retrieved for an answer. How a page’s content is structured with headings, paragraphs, and lists determines the likely chunk boundaries for storage.
- Vectorization — Each chunk is then converted into a numeric vector that captures its semantic meaning. These embeddings live in a vector database and enable systems to find chunks quickly. The quality of the vector depends on the clarity of the chunk’s text.
- Indexing — Systems will store additional metadata (URL, title, headings, metadata) to filter and rank results. Structured data like schema metadata is especially valuable.
- Retrieval — A user asks a question or performs a search and the system retrieves the most semantically similar chunks via a vector search. It re-ranks those chunks using metadata and other signals and then composes its answer while citing sources (sometimes).
The Case for Human-Accessible Content
There are many more reasons why digital accessibility is simply the right thing to do. It turns out that in addition to boosting SEO, accessibility best practices help LLMs crawl, chunk, store, and retrieve content more accurately.
During retrieval, small errors like missing text, ambiguous links, or poor heading order can fail to expose the best chunks. Let’s dive into how this can happen and what common accessibility pitfalls contribute to the confusion.
For Content Teams — Authors, Writers, Editors

Lack of descriptive “alt” text
While some LLMs can employ machine-vision techniques to “see” images as a human would, descriptive alt text verifies what they are seeing and the context in which the image is relevant. The same best practices for describing images for people will help LLMs accurately understand the content.

Out-of-order heading structures
Similar to semantic HTML, headings provide a clear outline of a page. Machines (and screen readers!) use heading structure to understand hierarchy and context. When a heading level skips from an <h2> to an <h4>, an LLM may fail to determine the proper relationship between content chunks. During retrieval, the model’s understanding is dictated by the flawed structure, not the content’s intrinsic importance. (Source: research thesis PDF, “Investigating Large Language Models ability to evaluate heading-related accessibility barriers”)

Descriptive and unique links
All of the accessibility barriers surrounding poor link practices affect how LLMs evaluate their importance. Link text is a short textual signal that is vectorized to make proper retrieval possible. Vague link text like “Click here” or “Learn More” does not provide valuable signals. In fact, the same “Learn More” text multiple times on a page can dilute the signals for the URLs they point to.
Using the same link text for more than one destination URLs creates a knowledge conflict. Like people, an LLM is subject to “anchoring bias,” which means it is likely to overweight the first link it processes and underweight or ignore the second, since they both have the same text signal.
Example of the duplicate link problem: <a href=“[URL-A]”>Duplicate Link Text</a>, and then later in the same article, <a href=“[URL-B]”>Duplicate Link Text</a>. Conversely, when the same URL is used more than once on a page, the same link text should be repeated exactly.

Logical order and readable content
Simple, direct sentences (one fact per sentence) produce cleaner embeddings for LLM retrieval. Human accessibility best practices of plain language and clear structure are the same practices that improve chunking and indexing for LLMs
For Technical Teams — IT, Developers, Engineers
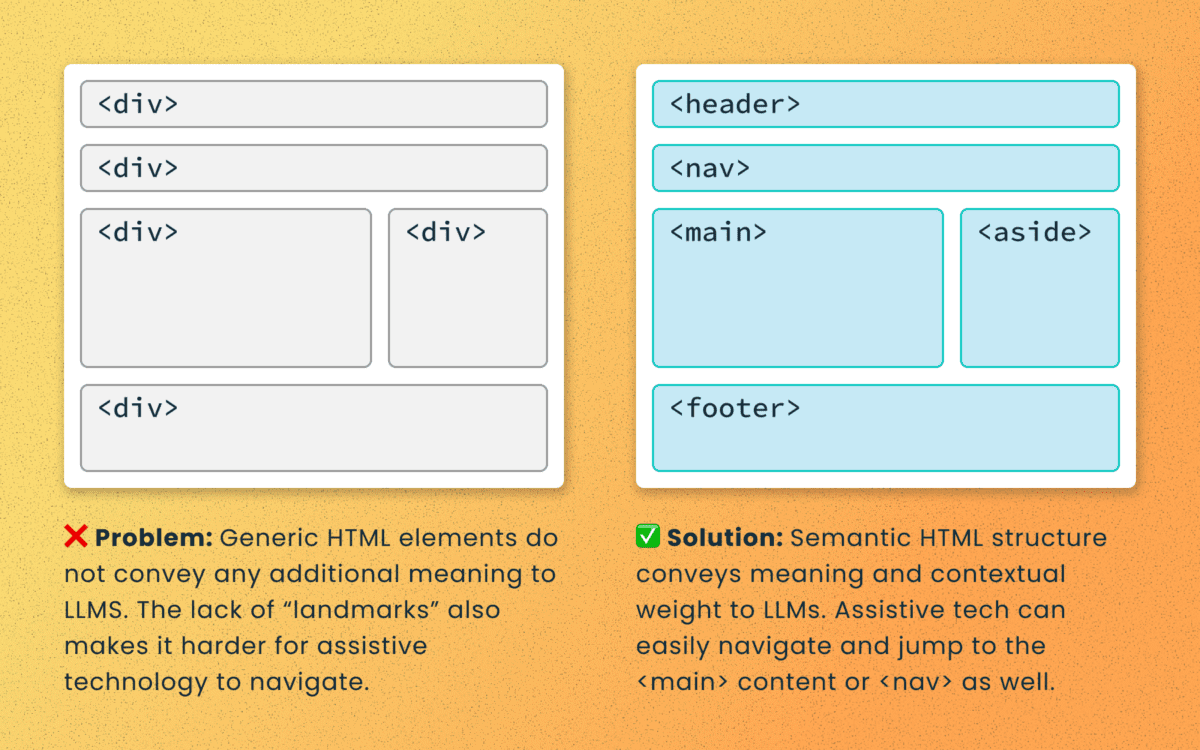
Poorly structured semantic HTML
Semantic elements (<article>, <nav>, <main>, <h1>, etc.) add context and suggest relative ranking weight. They make content boundaries explicit, which helps retrieval systems isolate your content from less important elements like ad slots or lists of related articles.

Lack of schema
This is technical and under the hood of your human-readable content. Machines love additional context and structured schema data is how facts are declared in code — product names, prices, event dates, authors, etc. Search engines have used schema for rich results and LLMs are no different. Right now, server-rendered schema data will guarantee the widest visibility, as not all crawlers execute client-side Javascript completely.
How to make accessibility even more actionable
The work of digital accessibility is often pushed to the bottom of the priority list. But once again, there are additional ways to frame this work as high value. While this work is beneficial for SEO, our recent research uncovers that it continues to be impactful in the new and evolving world of GEO.
If you need to frame an argument to those that control the investments of time and money, some talking points are:
- Accurate brand representation — Poor accessibility hides facts from LLMs. When customers ask an AI assistant for “best X for Y,” your content may not be shown — or worse, misrepresented. Fixing accessibility reduces brand risk and increases content authority.
- Engagement boost — Improvements that increase accurate citations and AI visibility can increase referral traffic, feature mentions, and lead quality. In a landscape where AI Answers are reducing click-through rates, keeping the traffic you have on your site for longer and building brand trust becomes vital.
- Increased exposure — Digital inclusion makes your content widely accessible to machines and the machines that assist humans. Think about a search engine as another human-assistive device, just like a keyboard or screen reader.
- Multi-pronged benefits — Accessibility improvement improves traditional SEO, can benefit mobile performance, and reduces the risks associated with accessibility compliance policies.
Staying steady in the storm
Let’s be clear — this summer was a “generative AI search freak out.” Content teams have scrambled to get smart about LLM-powered search quickly while search providers rolled out new tools and updates weekly. It’s been a tough ride in a rough sea of constant change.
To counter all that, know that the fundamentals are still strong. If your team has been using accessibility as a measure for content effectiveness and SEO discoverability, don’t stop now. If you haven’t yet started, this is one more reason to apply these principles tomorrow.
If you continue to have questions within this rapidly evolving landscape, talk to us about your questions around SEO, GEO, content strategy, and accessibility conformance. Ask about our training and documentation available for content teams.
Additional Reading
- AHREFs.com: Is SEO Dead? Real Data vs. Internet Hysteria
- SearchEngineJournal.com: How LLMs Interpret Content: How To Structure Information For AI Search
- InclusionHub.com: SEO and Web Accessibility: What You Need to Know (from 2020, but still relevant)
In 2026, the way people discover and engage with digital content has shifted. Traditional Search Engine Optimization (SEO) is no longer the only strategy that brings people to your website. Meet Generative Engine Optimization (GEO), the emerging frontier for organizations looking to earn visibility through AI-driven platforms like ChatGPT, Google’s Gemini, and Perplexity.
If your organization hasn’t begun adapting its content strategy for GEO, now is the time. Here’s what GEO is, why it matters, and how to start optimizing for it.
What is GEO and How Is It Different From SEO?
While SEO focuses on improving your visibility on traditional search engine results pages (SERPs) through keywords, backlinks, and technical performance, GEO is about making your content the answer in AI-generated responses.
Rather than presenting users with a list of links, GEO centers on AI tools that synthesize information. These platforms use large language models (LLMs) to provide direct answers to questions. Instead of competing for a top 10 ranking on Google, you’re aiming to be cited, summarized, or linked to by tools like Gemini or ChatGPT.
In short: SEO gets you found, GEO gets you featured.
Why GEO Matters in 2026
AI tools are no longer sidekicks to Google—they’re central to how people research, compare options, and make decisions. As of late 2025, ChatGPT receives over 4.5 billion monthly visits, while Perplexity processes over 500 million searches per month. Google remains the dominant force in online search with billions of daily visits, but with the direct integration of Gemini into search results, the way people find information is changing. Users can now get answers without ever clicking through to your website—a “zero-click search result.”
If your content isn’t showing up in AI answers, you’re missing visibility with a massive and growing segment of your audience. Depending on what your digital experience delivers, this affects brand recognition, traffic and lead potential, and your credibility as an authority in your space.
In 2026, AI summaries are the new front page of search.
How GEO Works: What AI Tools Are Looking For
Each generative engine has its quirks, but several patterns are emerging across platforms:
1. Structure Matters More Than Ever
AI tools rely on clear, structured content. Use schema markup generously—particularly FAQPage, Organization, Article, and Product types. Structured data helps AI understand your content contextually, making it easier to reference in generated answers.
Tip: Google’s Structured Data Markup Helper is a great place to start reviewing your schema.
2. E-E-A-T Principles Still Rule
Google’s Expertise, Experience, Authoritativeness, and Trustworthiness (E-E-A-T) framework, a core concept for SEO, now extends to AI tools like Gemini. Show credentials, cite data, link to reputable sources, and provide content authored by credible experts.
If you have certifications, awards, partnerships, or original research, feature them clearly.
3. Conversation > Keywords
GEO is less about keywords and more about natural language. Write in a conversational tone and frame your content in terms of questions and answers. Think: “What are the best family vacation spots in California?” instead of “California vacation destinations.”
4. Content Freshness is Key
AI platforms—especially Perplexity, which indexes content daily—prioritize content that’s up to date. Refresh evergreen posts annually and use a content calendar to track when to review content. Prioritize articles with titles like “Top” or “Best,” as these perform well in answer generation, particularly on ChatGPT.
5. Visuals Are Increasingly Important
Gemini and Perplexity are both investing in multimodal search. Media assets like charts, videos, and well-optimized images can increase the chance of being featured. Also make sure your image alt text, captions, and surrounding content are descriptive.
6. Prioritize Performance & Mobile-Responsiveness
A site that performs well on mobile loads quickly, displays clearly on small screens, and avoids frustrating interactions like unclickable buttons or pop-ups. Poor mobile performance—including slow Core Web Vitals—can hurt your rankings, which in turn reduces your visibility to LLMs that rely on search results as input sources.
Tool-Specific GEO Tips
Gemini (Google)
- Optimize for the Search Generative Experience (SGE) with crawlable content and Core Web Vitals in check.
- Use a hub and spoke content model to build topical authority. This model organizes content around a central “hub” topic page that then links to related and more detailed “spoke” pages.
- Regularly monitor impressions and click-through rates in Google Search Console. A dip in clicks with high impressions could signal that your content is being used in AI answers.
Perplexity
- With an emphasis on factual accuracy, source transparency, and user control over search scope, sources are essential. Focus on citations and factual, digestible content.
- Use Question & Answer formatting to align with Perplexity’s research focus.
- Include multimedia assets and data points that back up your authority—charts, diagrams, and maps in addition to video and images.
ChatGPT
- Embrace personalization. ChatGPT seeks out phrases like “top” or “best” that give users the feeling of receiving personalized insights.
- Optimize your About Us page to clearly articulate your mission and values. ChatGPT often uses this to evaluate trustworthiness and authority.
- Strengthen your backlink profile to compete with high-authority sources like Wikipedia, Reddit, and news outlets frequently cited by the model.
Tracking GEO Performance
A consequence of AI summaries is that websites may see a drop in clicks and visits within their analytics, particularly a decrease in organic traffic month over month. With users getting answers from AI-generated search responses, they may no longer need to visit your website for information. However, those users who do click through often stay longer and discover more pages than they did previously.
Websites may also see an increase in impressions or referrals from AI assistants. This data is increasingly important to track.
Even if AI tools don’t always send traffic directly, you can still measure their impact:
- Google Analytics 4 (GA4) Segmentation: Create segments by referral source (e.g., chat.openai.com, perplexity.ai, gemini.google.com) to track AI-specific sessions.
- Landing Page Analysis: AI tools often link deep into your site. Use GA4 to monitor which long-tail pages are receiving AI-generated traffic.
- Google Search Console: Identify FAQ-style queries with high impressions but low CTR. These may indicate your content is being summarized in AI answers.
What This Makes Possible
For organizations investing in GEO, the shift isn’t just about traffic—it’s about creating the foundation for how your brand shows up when decisions are made. When your content is structured, current, and authoritative, you’re positioned to be the answer AI platforms cite. That visibility translates into trust, consideration, and the ability to shape how your expertise is perceived across the platforms your audiences use most.
Organizations that optimize for GEO now are building systems that can adapt as AI search continues to evolve, ensuring their digital presence performs across both traditional and emerging channels.
Action Items for Digital Teams
- Audit your existing content with these optimization strategies in mind. You can use AI tools like Gemini to identify optimization opportunities for particular pages.
- Update schema across all major content types, especially Q&A and organizational pages.
- Refresh your high-performing or evergreen content regularly, especially pieces tied to seasons, events, or top lists.
- Revise your content strategy to include multimedia assets, structured data, and topic clustering.
- Optimize your About page and author bios to strengthen trust signals for LLMs.
Final Thoughts
Optimizing for GEO is a fundamental shift in how people find and interact with content. As AI-generated answers become a dominant part of the discovery experience, your organization’s ability to show up in these spaces affects whether you gain trust or go unnoticed.
By embracing schema, writing conversationally, and refreshing content with purpose, your digital presence can evolve to meet the moment—one where the best answer often wins over the best ranking.
Ready to optimize your content for AI-powered search? Let’s talk about what that looks like for your organization.
Today I learned about a military term that has come into the culture: VUCA, which stands for volatility, uncertainty, complexity, and ambiguity. That certainly describes our current times.
All of this VUCA makes me concentrate on what is stable and slow to change. Its easy to get distracted by that which changes quickly and shines in the light. Its harder to be grateful for what changes slowly. Its harder to see what those things might even be.
In the face of AI and the way it will transform all industries (if not now, very soon), its important to remember what AI can not yet do well. Maybe it will learn how to create a facsimile of these traits in the future as it becomes more “human” (trained on human data with all its flaws might mean it has embedded within it those traits we find undeniably human). However, these skills seem like the ones that can help us navigate the VUCA that is life today.
Be Curious
AI can ask follow-up questions for clarification, but it does not (yet) ask questions for its own curiosity. It asks when it has been directed to do something. It does not sit idle and wonder what the world is like beyond the walls of the chat window.
Humans and high-order animals have curiosity. We seek information and naturally have questions about our world — why is the sky blue? why does the wind blow? why do waves crash onto the shore?
In our operations, Oomph prides itself on Discovery. This is our chance to ask the big questions — why does your business work the way it does? why are those your goals? who is your audience you have vs. the audience you want?
In life and work, curiosity is one of our best traits. This means trying new tools, changing our processes and habits for improved outcomes, and exploring something new just to see what it can do. Even with all the VUCA in the world, approaching uncertainty with curiosity keeps us open and engaged with what we can learn next.
Use Judgement
Another important human trait is judgement, and this continues to be invaluable as humans are needed to evaluate AI outputs.
AI is very good at creating dozens, if not hundreds of outputs. In fact, probabilistic (not deterministic) output is the strength and sometimes weakness of AI — you almost never get the same answer twice.
Our human expertise is needed to curate these outputs. We need to discard what is average and unremarkable to find the outputs that are surprising and valuable. We need to use our judgement and experience to find the ideas that are applicable to the client, the project, and the moment. Given the same 100 outputs, the right ones might be a different selection depending on the problem we want to solve and the industry in which it will be applied.
Exude Empathy
In the world of design and creating software for humans, empathy is what drives the decisions we need to make. In the flow of vibe coding, our judgments will drive technical and architectural decisions while empathy drives interface design and product feature decisions. Humans are still the ones who need to find the problems that are worth solving.
The language on the page, the helpfulness of the tooltip, and the order in which the form elements appear are some examples of how empathy drives interactions. Empathy helps team members identify confusion and redundancy.
Further, until we are designing for AI Agents and robots as our product’s primary users, we are designing for humans. This means we need to continue to ask humans for feedback, monitor human behavior on our sites and in our apps, and understand why they make the decisions they make. All of this continues to make empathy an important human trait to cultivate.
Make Connections
Mike Bechtel, Chief Futurist at Deloitte Consulting, gave a talk at SXSW this year about how the future favors polymaths instead of specialists. His argument boils down to this: AI is a specialist at almost anything but what humans have shown over time is that the greatest inventions and insights come from disparate teams putting their expertise together or individuals making new connections between disciplines.
Novel ideas are mash-ups of existing ideas more than brand-new ideas that have never been thought of. And these mash-ups come from curious humans who have broad experience, not deep specialization. They are the ones who can identify and bring the specialists together if need be, but most of all, they can make the connections and see the bigger picture to create new approaches.
Support Culture
No matter how smart AI gets, it doesn’t “read the room.” It doesn’t build relationships between others, react to group dynamics, or pick up on body language. In an ambiguous human way, it does not sense when something “feels off.”
In group settings, humans command culture. AI won’t directly help you build trust with a client. It won’t read the faces in the room or over Zoom and pause for questions. It won’t sense that people are not engaging and reacting, and therefore you need to change a tactic while speaking. AI is interested in the facts and not the feelings.
Broad team culture and the culture that exists between individuals is built and nurtured by the humans within them. AI might help you craft a good sales pitch, internal memo, or provide ice breaker ideas, but in the end, humans deliver it. Mentoring, supporting culture, collaborating, and building trust continue to be human endeavors.
Break Patterns
AI is very good at replicating patterns and what has already been created. AI is very good at using its vast amount of data to emphasize best practices with patterns that are the most prevalent and potentially the most successful. But it won’t necessarily find ways to break existing patterns to create new and disruptive ones.
Asking great questions (being curious), applying our experience and judgement, and doing it all with empathy for the humans we support leads to creative, pattern-breaking solutions that AI has not seen before. Best practices don’t stay the best forever. Changes in technology and our interface with it create new best practices.
The easiest answer (the common denominator that AI may reach for) is not always the best solution. There is a time and a place to repeat common patterns for efficiency, but then there are times when we need to create new patterns. Humans will continue to be the ones who can make that judgement.
Be Human
AI will continue to evolve. It may get better at some of the attributes I mention — or at best, it may get better at looking like it has empathy, supports culture, and mashes existing patterns together to create new ones. But for humans, these traits come more naturally. They don’t have to be trained or prompted to use these traits.
Of all these traits, curiosity may be the most important and impactful one. AI has become our answer-engine, making it less necessary to know it all. But we need to continue to be curious, to wonder about “what if?” AI shouldn’t tell us what to ask, but it should support us in asking deeper questions and finding disparate ideas that could create a new approach.
We no longer need to learn everything. All the answers to what is already known can be provided. It is up to humans to continue with curiosity into what we do not yet know.
The Drupal Association brought a new challenge to the Drupal community this past summer. At the beginning of May 2024, Dries Buytaert, the founder and leading visionary for the Drupal platform, announced an ambitious plan codenamed Starshot. The community rapidly came together around the concept and started planning how to make this vision of the future a reality, including Oomph.
What is Starshot/Drupal CMS?
Codename Starshot is now known as Drupal CMS. Drupal is a free, open-source content management system (CMS) where authors and developers build and maintain websites. Drupal has been around since 2001, and in the past, it was focused on being a developer-friendly platform that supports complex integrations and custom features.
Drupal CMS is a reimagining of Drupal for a wider market. Currently, Drupal successfully supports the complexities that governments, high-volume editorial sites, and membership organizations require. But, the barrier to entry for those that wanted to start with a small, simple site was too high.
Drupal CMS is the community’s solution to drastically lower the barrier to entry by providing a new onboarding and page-building experience, recipes for common features, advanced SEO features, and “AI Agents” that assist authors with content migration and site-building acceleration. Dries challenged the community to start building towards a working prototype in less than 4 months, in time to demonstrate significant progress for the audience at DrupalCon Barcelona in mid-September.
The Contact Form Track
The Contact Form is an official recommended recipe. As the name suggests, its purpose is to provide a Recipe that installs the necessary modules and default content to support a useful, but simple, Contact Form.
The primary user persona for Drupal CMS is a non-technical Marketer or Digital Strategist. Someone who wants to set up a simple website to promote themselves, a product, and/or a service. A Contact Form should start simple, but be ready for customization such as integrations with popular email newsletter services for exporting contacts and opting into receiving email.
Research and Competitive Analysis
Drupal CMS aims to compete with juggernauts like WordPress and relative newcomers like SquareSpace, Wix, and Webflow. To create a Contact Form that could compete with these well-known CMSs, our first step was to do some competitive research.
We went in two directions for the competitive analysis (Figma whiteboard). First, we researched what kinds of experiences and default contact forms competitor CMSs provided. Second, we took stock of common Contact Form patterns, including those from well-known SAAS products. We wanted to see the kinds of fields that sales lead generation forms typically leveraged. With both of these initiatives, we learned a few things quickly:
- The common fields for a simple Contact Form are generally consistent from platform to platform
- More complex sales lead forms also had much in common, though every form had something custom that directly related to the product offered
- WordPress does not have a Contact Form solution out of the box! Site owners need to research commonly used plugins to achieve this
Our approach was starting to take shape. We internally documented our decisions and high-value MVP requirements and presented them to the advisory board for feedback. With that, we were off to create the start of our Contact Form recipe.
Recipe and Future Phases
Phil Frilling started the Contact Form recipe, which is currently under peer review. The recipe is barebones for Phase 1 and will install the required modules to support a default Contact Form and email the site owner when messages are received. Once the initial recipe is accepted, a round of testing, documentation, and additional UI in a custom module may be required.
Our plans include additional fields set as optional for the site owner to turn on or off as they need. Some customization will be supported in a non-technical user-friendly way, but all the power of Drupal WebForms will be available to those that want to dig deeper into customizing their lead forms.
In the short term, we are proposing:
- Database storage of contacts that safeguards valuable leads that come in through forms
- Quick integrations with common CRMs and Newsletter providers
- Enhanced point-and-click admin UI through the in-progress Experience Builder
- Advanced fields to handle specialty data, like price ranges, date ranges, and similar
- Conditional defaults: Through the initial set up, when a site owner specifies an Editorial site they get one default Contact Form, while someone who specifies E-commerce gets another default Contact Form
- Feedback mechanism to request new fields
Next stop, the Moon
DrupalCon Barcelona took place last week, September 24 through 27, 2024, and the Drupal CMS prototype was displayed for all to see. Early 2025 is the next target date for a market-ready version of Drupal CMS. The community is continuing to push hard to create a fantastic future for the platform and for authors who are dissatisfied with the current CMS marketplace.
Oomph’s team will continue to work on the Contact Form Track while contributing in other ways with the full range of skills we have. The great part about such a large and momentous initiative as Drupal CMS is that the whole company can be involved, and each can contribute from their experience and expertise.
We’ll continue to share our progress in the weeks to come!
Thanks!
Track Lead J. Hogue with Philip Frilling contributing engineer, Akili Greer and Rachel Hart researchers, and thanks to Rachel Hart again for bringing the Contact Form Track Lead to Oomph for consideration.
Oomph has been quiet about our excitement for artificial intelligence (A.I.). While the tech world has exploded with new A.I. products, offerings, and add-ons to existing product suites, we have been formulating an approach to recommend A.I.-related services to our clients.
One of the biggest reasons why we have been quiet is the complexity and the fast-pace of change in the landscape. Giant companies have been trying A.I. with some loud public failures. The investment and venture capitalist community is hyped on A.I. but has recently become cautious as productivity and profit have not been boosted. It is a familiar boom-then-bust of attention that we have seen before — most recently with AR/VR after the Apple Vision Pro five months ago and previously with the Metaverse, Blockchain/NFTs, and Bitcoin.
There are many reasons to be optimistic about applications for A.I. in business. And there continue to be many reasons to be cautious as well. Just like any digital tool, A.I. has pros and cons and Oomph has carefully evaluated each. We are sharing our internal thoughts in the hopes that your business can use the same criteria when considering a potential investment in A.I.
Using A.I.: Not If, but How
Most digital tools now have some kind of A.I. or machine-learning built into them. A.I. has become ubiquitous and embedded in many systems we use every day. Given investor hype for companies that are leveraging A.I., more and more tools are likely to incorporate A.I.
This is not a new phenomenon. Grammarly has been around since 2015 and by many measures, it is an A.I. tool — it is trained on human written language to provide contextual corrections and suggestions for improvements.
Recently, though, embedded A.I. has exploded across markets. Many of the tools Oomph team members use every day have A.I. embedded in them, across sales, design, engineering, and project management — from Google Suite and Zoom to Github and Figma.
The market has already decided that business customers want access to time-saving A.I. tools. Some welcome these options, and others will use them reluctantly.
Either way, the question has very quickly moved from should our business use A.I. to how can our business use A.I. tools responsibly?
The Risks that A.I. Pose
Every technological breakthrough comes with risks. Some pundits (both for and against A.I. advancements) have likened its emergence to the Industrial Revolution of the early 20th century. And a high-level of positive significance is possible, while the cultural, societal, and environmental repercussions could also follow a similar trajectory.
A.I. has its downsides. When evaluating A.I. tools as a solution to our client’s problems, we keep this list of drawbacks and negative effects handy, so that we may review it and think about how to mitigate their negative effects:
- A.I. is built upon biased and flawed data
- Bias & flawed data leads to the perpetuation of stereotypes
- Flawed data leads to Hallucinations & harms Brands
- Poor A.I. answers erode Consumer Trust
- A.I.’s appetite for electricity is unsustainable
We have also found that our company values are a lens through which we can evaluate new technology and any proposed solutions. Oomph has three cultural values that form the center of our approach and our mission, and we add our stated 1% For the Planet commitment to that list as well:
- Smart
- Driven
- Personal
- Environmentally Committed
For each of A.I.’s drawbacks, we use the lens of our cultural values to guide our approach to evaluating and mitigating those potential ill effects.
A.I. is built upon biased and flawed data
At its core, A.I. is built upon terabytes of data and billions, if not trillions, of individual pieces of content. Training data for Large Language Models (LLMs) like Chat GPT, Llama, and Claude encompass mostly public content as well as special subscriptions through relationships with data providers like the New York Times and Reddit. Image generation tools like Midjourney and Adobe Firefly require billions of images to train them and have skirted similar copyright issues while gobbling up as much free public data as they can find.
Because LLMs require such a massive amount of data, it is impossible to curate those data sets to only what we may deem as “true” facts or the “perfect” images. Even if we were able to curate these training sets, who makes the determination of what to include or exclude?
The training data would need to be free of bias and free of sarcasm (a very human trait) for it to be reliable and useful. We’ve seen this play out with sometimes hilarious results. Google “A.I. Overviews” have told people to put glue on pizza to prevent the cheese from sliding off or to eat one rock a day for vitamins & minerals. Researchers and journalists traced these suggestions back to the training data from Reddit and The Onion.
Information architects have a saying: “All Data is Dirty.” It means no one creates “perfect” data, where every entry is reviewed, cross-checked for accuracy, and evaluated by a shared set of objective standards. Human bias and accidents always enter the data. Even the simple act of deciding what data to include (and therefore, which data is excluded) is bias. All data is dirty.
Bias & flawed data leads to the perpetuation of stereotypes
Many of the drawbacks of A.I. are interrelated — All data is dirty is related to D.E.I. Gender and racial biases surface in the answers A.I. provides. A.I. will perpetuate the harms that these biases produce as they become easier and easier to use and more and more prevalent. These harms are ones which society is only recently grappling with in a deep and meaningful way, and A.I. could roll back much of our progress.
We’ve seen this start to happen. Early reports from image creation tools discuss a European white male bias inherent in these tools — ask it to generate an image of someone in a specific occupation, and receive many white males in the results, unless that occupation is stereotypically “women’s work.” When AI is used to perform HR tasks, the software often advances those it perceives as males more quickly, and penalizes applications that contain female names and pronouns.
The bias is in the data and very, very difficult to remove. The entirety of digital written language over-indexes privileged white Europeans who can afford the tools to become authors. This comparably small pool of participants is also dominantly male, and the content they have created emphasizes white male perspectives. To curate bias out of the training data and create an equally representative pool is nearly impossible, especially when you consider the exponentially larger and larger sets of data new LLM models require for training.
Further, D.E.I. overflows into environmental impact. Last fall, the Fifth National Climate Assessment outlined the country’s climate status. Not only is the U.S. warming faster than the rest of the world, but they directly linked reductions in greenhouse gas emissions with reducing racial disparities. Climate impacts are felt most heavily in communities of color and low incomes, therefore, climate justice and racial justice are directly related.
Flawed data leads to “Hallucinations” & harms Brands
“Brand Safety” and How A.I. can harm Brands
Brand safety is the practice of protecting a company’s brand and reputation by monitoring online content related to the brand. This includes content the brand is directly responsible for creating about itself as well as the content created by authorized agents (most typically customer service reps, but now AI systems as well).
The data that comes out of A.I. agents will reflect on the brand employing the agent. A real life example is Air Canada. The A.I. chatbot gave a customer an answer that contradicted the information in the URL it provided. The customer chose to believe the A.I. answer, while the company tried to say that it could not be responsible if the customer didn’t follow the URL to the more authoritative information. In court, the customer won and Air Canada lost, resulting in bad publicity for the company.
Brand safety can also be compromised when a 3rd party feeds A.I. tools proprietary client data. Some terms and condition statements for A.I. tools are murky while others are direct. Midjourney’s terms state,
“By using the Services, You grant to Midjourney […] a perpetual, worldwide, non-exclusive, sublicensable no-charge, royalty-free, irrevocable copyright license to reproduce, prepare derivative works of, publicly display, publicly perform, sublicense, and distribute text and image prompts You input into the Services”
Midjourney’s Terms of Service Statement
That makes it pretty clear that by using Midjourney, you implicitly agree that your data will become part of their system.
The implication that our client’s data might become available to everyone is a huge professional risk that Oomph avoids. Even using ChatGPT to provide content summaries on NDA data can open hidden risks.
What are “Hallucinations” and why do they happen?
It’s important to remember how current A.I. chatbots work. Like a smartphone’s predictive text tool, LLMs form statements by stitching together words, characters, and numbers based on the probability of each unit succeeding the previously generated units. The predictions can be very complex, adhering to grammatical structure and situational context as well as the initial prompt. Given this, they do not truly understand language or context.
At best, A.I. chatbots are a mirror that reflects how humans sound without a deep understanding of what any of the words mean.
A.I. systems are trying its best to provide an accurate and truthful answer without a complete understanding of the words it is using. A “hallucination” can occur for a variety of reasons and it is not always possible to trace their origins or reverse-engineer them out of a system.
As many recent news stories state, hallucinations are a huge problem with A.I. Companies like IBM and McDonald’s can’t get hallucinations under control and have pulled A.I. from their stores because of the headaches they cause. If they can’t make their investments in A.I. pay off, it makes us wonder about the usefulness of A.I. for consumer applications in general. And all of these gaffes hurt consumer’s perception of the brands and the services they provide.
Poor A.I. answers erode Consumer Trust
The aforementioned problems with A.I. are well-known in the tech industry. In the consumer sphere, A.I. has only just started to break into the public consciousness. Consumers are outcome-driven. If A.I. is a tool that can reliably save them time and reduce work, they don’t care how it works, but they do care about its accuracy.
Consumers are also misinformed or have a very surface level understanding of how A.I. works. In one study, only 30% of people correctly identified six different applications of A.I. People don’t have a complete picture of how pervasive A.I.-powered services already are.
The news media loves a good fail story, and A.I. has been providing plenty of those. With most of the media coverage of A.I. being either fear-mongering (“A.I. will take your job!”) or about hilarious hallucinations (“A.I. suggests you eat rocks!”), consumers will be conditioned to mistrust products and tools labeled “A.I.”
And for those who have had a first-hand experience with an A.I. tool, a poor A.I. experience makes all A.I. seem poor.
A.I.’s appetite for electricity is unsustainable
The environmental impact of our digital lives is invisible. Cloud services that store our lifetime of photographs sound like featherly, lightweight repositories that are actually giant, electricity-guzzling warehouses full of heat-producing servers. Cooling these data factories and providing the electricity to run them are a major infrastructure issue cities around the country face. And then A.I. came along.
While difficult to quantify, there are some scientists and journalists studying this issue, and they have found some alarming statistics:
- Training GPT-3 required more than 1,200 MWh which led to 500 metric tons of greenhouse gas emissions — equivalent to the amount of energy used for 1 million homes in one hour and the emissions of driving 1 million miles. GPT-4 has even greater needs.
- Research suggests a single generative A.I. query consumes energy at four or five times the magnitude of a typical search engine request.
- Northern Virginia needs the equivalent of several large nuclear power plants to serve all the new data centers planned and under construction.
- In order to support less consumer demand on fossil fuels (think electric cars, more electric heat and cooking), power plant executives are lobbying to keep coal-powered plants around for longer to meet increased demands. Already, soaring power consumption is delaying coal plant closures in Kansas, Nebraska, Wisconsin, and South Carolina.
- Google emissions grew 48% in the past five years in large part because of its wide deployment of A.I.
While the consumption needs are troubling, quickly creating more infrastructure to support these needs is not possible. New energy grids take multiple years and millions if not billions of dollars of investment. Parts of the country are already straining under the weight of our current energy needs and will continue to do so — peak summer demand is projected to grow by 38,000 megawatts nationwide in the next five years.
While a data center can be built in about a year, it can take five years or longer to connect renewable energy projects to the grid. While most new power projects built in 2024 are clean energy (solar, wind, hydro), they are not being built fast enough. And utilities note that data centers need power 24 hours a day, something most clean sources can’t provide. It should be heartbreaking that carbon-producing fuels like coal and gas are being kept online to support our data needs.
Oomph’s commitment to 1% for the Planet means that we want to design specific uses for A.I. instead of very broad ones. The environmental impact of A.I.’s energy demands is a major factor we consider when deciding how and when to use A.I.
Using our Values to Guide the Evaluation of A.I.
As we previously stated, our company values provide a lens through which we can evaluate A.I. and look to mitigate its negative effects. Many of the solutions cross over and mitigate more than one effect and represent a shared commitment to extracting the best results from any tool in our set
Smart
- Limit direct consumer access to the outputs of any A.I. tools, and put a well-trained human in the middle as curator. Despite the pitfalls of human bias, it’s better to be aware of them rather than allow A.I. to run unchecked
- Employ 3rd-party solutions with a proven track-record of hallucination reduction
Driven
- When possible, introduce a second proprietary dataset that can counterbalance training data or provide additional context for generated answers that are specific to the client’s use case and audience
- Restrict A.I. answers when qualifying, quantifying, or categorizing other humans, directly or indirectly
Personal
- Always provide training to authors using A.I. tools and be clear with help text and microcopy instructions about the limitations and biases of such datasets
1% for the Planet
- Limit the amount of A.I. an interface pushes at people without first allowing them to opt in — A.I. should not be the default
- Leverage “green” data centers if possible, or encourage the client using A.I. to purchase carbon offset credits
In Summary
While this article feels like we are strongly anti-A.I., we still have optimism and excitement about how A.I. systems can be used to augment and support human effort. Tools created with A.I. can make tasks and interactions more efficient, can help non-creatives jumpstart their creativity, and can eventually become agents that assist with complex tasks that are draining and unfulfilling for humans to perform.
For consumers or our clients to trust A.I., however, we need to provide ethical evaluation criteria. We can not use A.I. as a solve-all tool when it has clearly displayed limitations. We aim to continue to learn from others, experiment ourselves, and evaluate appropriate uses for A.I. with a clear set of criteria that align with our company culture.
To have a conversation about how your company might want to leverage A.I. responsibly, please contact us anytime.
Additional Reading List
- “The Politics of Classification” (YouTube). Dan Klyn, guest lecture at UM School of Information Architecture. 09 April 2024. A review of IA problems vs. AI problems, how classification is problematic, and how mathematical smoothness is unattainable.
- “Models All the Way Down.” Christo Buschek and Jer Thorp, Knowing Machines. A fascinating visual deep dive into training sets and the problematic ways in which these sets were curated by AI or humans, both with their own pitfalls.
- “AI spam is already starting to ruin the internet.” Katie Notopoulos, Business Insider, 29 January 2024. When garbage results flood Google, it’s bad for users — and Google.
- Racial Discrimination in Face Recognition Technology, Harvard, 24 October 2020. The title of this article explains itself well.
- Women are more likely to be replaced by AI, according to LinkedIn, Fast Company, 04 April 2024. Many workers are worried that their jobs will be replaced by artificial intelligence, and a growing body of research suggests that women have the most cause for concern.
- Brand Safety and AI, Writer.com. An overview of what brand safety means and how it is usually governed.
- AI and designers: the ethical and legal implications, UX Design, 25 February 2024. Not only can using training data potentially introduce legal troubles, but submitting your data to be processed by A.I. does as well.
- Can Generative AI’s Hallucination Problem be Overcome? Louis Poirier, C3.ai. 31 August 2023. A company claims to have a solution for A.I. hallucinations but doesn’t completely describe how in their marketing.
- Why AI-generated hands are the stuff of nightmares, explained by a scientist, Science Focus, 04 February 2023. Whether it’s hands with seven fingers or extra long palms, AI just can’t seem to get it right.
- Sycophancy in Generative-AI Chatbots, NNg. 12 January 2024. Human summary: Beyond hallucinations, LLMs have other problems that can erode trust: “Large language models like ChatGPT can lie to elicit approval from users. This phenomenon, called sycophancy, can be detected in state-of-the-art models.”
- Consumer attitudes towards AI and ML’s brand usage U.S. 2023. Valentina Dencheva, Statistica. 09 February 2023
- What the data says about Americans’ views of artificial intelligence. Pew Research Center. 21 November 2023
- Exploring the Spectrum of “Needfulness” in AI Products. Emily Campbull, The Shape of AI. 28 March 2024
- AI’s Impact On The Future Of Consumer Behavior And Expectations. Jean-Baptiste Hironde, Forbes. 31 August 2023.
- Is generative AI bad for the environment? A computer scientist explains the carbon footprint of ChatGPT and its cousins. The Conversation. 23 May 2023
Everyone’s been saying it (and, frankly, we tend to agree): We are currently in unprecedented times. It may feel like a cliche. But truly, when you stop and look around right now, not since the advent of the first consumer-friendly smartphone in 2008 has the digital web design and development industry seen such vast technological advances.
A few of these innovations have been kicking around for decades, but they’ve only moved into the greater public consciousness in the past year. Versions of artificial intelligence (AI) and chatbots have been around since the 1960s and even virtual reality (VR)/augmented reality (AR) has been attempted with some success since the 1990s (That Starner). But now, these technologies have reached a tipping point as companies join the rush to create new products that leverage AI and VR/AR.
What should we do with all this change? Let’s think about the immediate future for a moment (not the long-range future, because who knows what that holds). We at Oomph have been thinking about how we can start to use this new technology now — for ourselves and for our clients. Which ideas that seemed far-fetched only a year ago are now possible?
For this article, we’ll take a closer look at VR/AR, two digital technologies that either layer on top of or fully replace our real world.
VR/AR and the Vision Pro
Apple’s much-anticipated launch into the headset game shipped in early February 2024. With it came much hype, most centered around the price tag and limited ecosystem (for now). But after all the dust has settled, what has this flagship device told us about the future?
Meta, Oculus, Sony, and others have been in this space since 2017, but the Apple device has debuted a better experience in many respects. For one, Apple nailed the 3D visuals, using many cameras and low latency to reproduce a digital version of the real world around the wearer— in real time. All of this tells us that VR headsets are moving beyond gaming applications and becoming more mainstream for specific types of interactions and experiences, like virtually visiting the Eiffel Tower or watching the upcoming Summer Olympics.
What Is VR/AR Not Good At?
Comfort
Apple’s version of the device is large, uncomfortable, and too heavy to wear for long. And its competitors are not much better. The device will increasingly become smaller and more powerful, but for now, wearing one as an infinite virtual monitor for the entire workday is impossible.
Space
VR generally needs space for the wearer to move around. The Vision Pro is very good at overlaying virtual items into the physical world around the wearer, but for an application that requires the wearer to be fully immersed in a virtual world, it is a poor experience to pantomime moving through a confined space. Immersion is best when the movements required to interact are small or when the wearer has adequate space to participate.
Haptics
“Haptic” feedback is the sense that physical objects provide. Think about turning a doorknob: You feel the surface, the warmth or coolness of the material, how the object can be rotated (as opposed to pulled like a lever), and the resistance from the springs.
Phones provide small amounts of haptic feedback in the form of vibrations and sounds. Haptics are on the horizon for many VR platforms but have yet to be built into headset systems. For now, haptics are provided by add-on products like this haptic gaming chair.
What Is VR/AR Good For?
Even without haptics and free spatial range, immersion and presence in VR is very effective. It turns out that the brain only requires sight and sound to create a believable sense of immersion. Have you tried a virtual roller coaster? If so, you know it doesn’t take much to feel a sense of presence in a virtual environment.
Live Events
VR and AR’s most promising applications are with live in-person and televised events. In addition to a flat “screen” of the event, AR-generated spatial representations of the event and ways to interact with the event are expanding. A prototype video with Formula 1 racing is a great example of how this application can increase engagement with these events.
Imagine if your next virtual conference were available in VR and AR. How much more immersed would you feel?
Museum and Cultural Institution Experiences
Similar to live events, AR can enhance museum experiences greatly. With AR, viewers can look at an object in its real space — for example, a sarcophagus would actually appear in a tomb — and access additional information about that object, like the time and place it was created and the artist.
Museums are already experimenting with experiences that leverage your phone’s camera or VR headsets. Some have experimented with virtually showing artwork by the same artist that other museums own to display a wider range of work within an exhibition.
With the expansion of personal VR equipment like the Vision Pro, the next obvious step is to bring the museum to your living room, much like the National Gallery in London bringing its collection into public spaces (see bullet point #5).
Try Before You Buy (TBYB)
Using a version of AR with your phone to preview furniture in your home is not new. But what other experiences can benefit from an immersive “try before you buy” experience?
- Test-drive a new car with VR, or experience driving a real car on a real track in a mixed-reality game. As haptic feedback becomes more prevalent, the experience of test-driving will become even closer to the real thing.
- Even small purchases have been using VR and AR successfully to trial their products, including AR for fashion retail, eyeglass virtual try-ons, and preview apps for cosmetics. Even do-it-yourself retailer Lowe’s experimented with fully haptic VR in 2018. But those are all big-name retailers. The real future for VR/AR-powered TBYB experiences will allow smaller companies to jump into the space, like Shopify enabled for its merchants.
- Visit destinations before traveling. With VR, you could visit fragile ecosystems without affecting the physical environment or get a sense of the physical space before traveling to a new spot. Visitors who require special assistance could preview the amenities beforehand. Games have been developed for generic experiences like deep sea diving, but we expect more specific travel destinations to provide VR experiences of their own, like California’s Redwood Forest.
What’s Possible With VR/AR?
The above examples of what VR/AR is good at are just a few ways the technology is already in use — each of which can be a jumping-off point for leveraging VR/AR for your own business.
But what are some new frontiers that have yet to be fully explored? What else is possible?
- What if a digital sculptor or 3D model maker could create new three-dimensional models in a three-dimensional virtual space? The application for architects and urban planners is just as impactful.
- What if medical training could be immersive, anatomically accurate, and reduce the need for cadavers? What if rare conditions could be simulated to increase exposure and aid in accurate diagnoses?
- What if mental health disorders could be treated with the aid of immersive virtual environments? Exposure therapy can aid in treating and dealing with anxiety, depression, and PTSD.
- What if highly skilled workers could have technical mentors virtually assist and verify the quality of a build? Aerospace, automotive, and other manufacturing industry experts could visit multiple locations virtually and go where they’re needed most.
- What if complex mathematic-based sciences could provide immersive, data-manipulative environments for exploration? Think of the possibilities for fields like geology, astronomy, and climate change.
- What if movies were told from a more personal point of view? What if the movie viewer felt more like a participant? How could someone’s range of experiences expand with such immersive storytelling?
Continue the AR/VR Conversation
The Vision Pro hasn’t taken the world by storm, as Apple likely hoped. It may still be too early for the market to figure out what AR/VR is good for. But we think it won’t go away completely, either. With big investments like Apple’s, it is reasonable to assume the next version will find a stronger foothold in the market.
Here at Oomph, we’ll keep pondering and researching impactful ways that tomorrow’s technology can help solve today’s problems. We hope these ideas have inspired some of your own explorations, and if so, we’d love to hear more about them.
Drop us a line and let’s chat about how VR/AR could engage your audience.
In the age of hyper-personalization by the likes of Amazon and Netflix, customized user experiences are now table stakes for digital platforms. Businesses that invest in personalization are rewarded with loyalty and revenue. Those that don’t, get left behind.
But making that investment isn’t a straightforward affair. Many services that pitch themselves as personalization tools don’t even come close to creating a truly customized experience. And today’s savvy web users aren’t fooled:
- 74% of customers feel frustrated when website content isn’t personalized.
- 84% of consumers say being treated like a person, not a number, is important to winning their business.
Where we’ve seen businesses stumble is in substituting personification for true personalization. While personalization involves tailoring content based on direct personal information, personification is based on categories of consumers, not individual people.
Here’s what you need to know about the difference.
Perils of Personification
Gartner defines personification as “the delivery of relevant digital experiences to individuals based on their inferred membership in a defined customer segment, rather than their personal identity.” It’s the digital equivalent of calling someone “buddy” or “champ” because you can’t remember their name. I know that I know you, but I don’t know who you are.
Personification tools can track user behavior and use AI to place users into, say, one of several marketing personas you’ve developed. But in terms of driving meaningful, personalized interactions with users, personification falls down.
Here are a few critical issues with commonly used personification tools:
User Session Data
Information about a user’s interactions with an application is stored temporarily on the application’s server, not the browser.
EXAMPLE: During this session, I see that you’ve visited a piece of content that falls in a specific category. For the rest of your session, I can serve up other content tagged with the same category (often in Featured, Related, or You May Also Like sections).
PROBLEM 1: As soon as the browser session is closed, the user data is lost.
PROBLEM 2: The moment you switch from one device (e.g. mobile) to another (e.g. tablet) you lose all session data.
Contextual Data
Marketing automation or location intelligence software can use AI to gather environmental data about a user to deliver customized content or services.
EXAMPLE: I see that you’re in Los Angeles, California. Knowing your local weather, time zone, and other regional attributes, I can tailor the content you see to be more specific to your area.
PROBLEM: I have to ask you first if I can track your location, and you might say no.
First Party Cookie Data
By storing information about a user’s behavior directly on a domain, site owners can collect analytics data and remember language settings, among other functions.
EXAMPLE: Last time you visited my website, you commented on a certain piece of content. I may even have asked, “Do you want to see more of this type of content?” Now that you’re back, I can serve up newly published content of the same type. I can even feature it right on the homepage.
PROBLEM 1: I need to ask you if I can use cookies with you, and you can say no.
PROBLEM 2: If you clear the cookies in your browser, I’ll lose that valuable data.
PROBLEM 3: Another family member is using the same application on the same device, and now I’m getting mixed signals. This is completely messing with my AI.
Bottom line: personification is not really personalization. Even worse, you may lose your data and have to start from square one. To deliver true personalization, you need first-party data from authenticated users. Instead of guessing who your customer is, get to know who they really are.
Next-Level Personalization
True personalization is difficult to achieve outside of a digital platform, where people register as users (versus just casually visiting a website). Once someone becomes an authenticated user, it’s easier to learn a number of things about them.
83% of consumers are willing to share their data to enable personalized experiences. Platform users in particular are more open to providing personal information, because they’re specifically looking for a customized experience. With that first-party data, you can track preferences and interactions to improve the user experience. And you’re not going to lose the historical data when a user closes a session or clears their cookies.
Here are some key benefits:
- I actually know who you are, and over time I can continue to learn more about you and your interests. Plus, I’ll only lose that data if you quit my tool, service, or platform.
- Your data follows you across any devices where you use my application (mobile, tablet, desktop, etc.).
- I can start a two-way conversation with you, so you can tell me how you want to personalize your experience and what kind of content you want to see.
- I can reach out to you with personalized suggestions, driving more engagement and giving you a reason to return more often.
- While you can always say no to first-party cookies if you have privacy concerns, by signing up for my platform, you’re indicating a level of trust and consent.
Looking for Middle Ground?
In the end, you’ll deliver the best personalization (and earn the most engagement) by building an interactive platform and leveraging first-party data. But what if you have a decent website, and you’re not ready to shift to a platform?
You could approach it as a testing ground for personalization instead. By creating a series of micro-interactions using personification tools, you can test whether your users actually want a personalized experience, and if so, what they want to personalize.
Let’s say you’re a news outlet. You could just let people come and read your content online. At the next level, you can try to guess who they are through personification (via cookie requests, location prompts, etc.). If users are interacting with your prompts, it’s likely they’re interested in having a personalized experience.
Finally, you could build a platform for registered users and offer true personalization. You’ll not only deliver a better user experience, you’ll increase engagement and return visits — not to mention sales and other revenue.
At whatever level you can, go the extra mile and give your users what they want. We’re happy to help! Contact us today to learn more.