
Structured content distribution is the decoupling of content from presentation through a headless CMS and Content as a Service (CaaS) architecture. It is a sound strategy for organizations managing complex content distribution networks across multiple channels.
To be the most successful, this digital transformation requires organizations to change both their publishing workflows and their content ownership structures. Governance complexity affects 41% of CaaS adopters (PDF), workflow mismatches impact a third, and training requirements average 14 to 18 weeks.
We have implemented these systems for clients in healthcare, financial services, and higher education, and the pattern is consistent: the three failures that kill structured content initiatives are the preview gap, the ownership vacuum, and the training deficit. Here is what we have learned about each one — and what actually works.
The Promise
The pitch for structured content distribution is compelling: create content once, store it as modular data in a headless CMS, deliver it via API to any channel (web, mobile, kiosks, AI agents) without reformatting. The CaaS market is projected to reach $2.8 billion by 2035, and over 65% of enterprises have adopted headless CMS architectures.
What they do not tell you is that integration challenges affect 46% of adopters using legacy CMS platforms, and that 31% of enterprises encounter deployment delays exceeding six months. The technology works, but the governance requires just as much attention and is often overlooked. We have seen this avoidable pattern repeat across many structured content implementations.
Why Do Structured Content Migrations Stall?
In short, because organizations implement the technology without redesigning how their teams create, review, approve, and own content. That’s the governance problem.
A headless CMS decouples content from presentation. But most editorial teams have spent years, sometimes decades, working in systems where creating content and seeing how it looks are the same activity. WordPress, Drupal, and even SharePoint have a visual editing experience: build a page, see the page, publish the page.
Structured content does not work this way. Authors fill in fields like title, body, metadata, and related entries to publish content objects, not pages. As one analysis of Contentful’s editorial interface notes, “content editors work in structured content entry forms without seeing how content will render in production.” The front-end determines how those objects appear to users.
That architectural distinction is the correct one for consistent omnichannel delivery. It is also the one most likely to break editorial workflow expectations when teams do not deliberately plan for this big shift. In our experience, three governance failures account for the vast majority of structured content stalls.
What Is the Preview Gap, and Why Does It Derail Teams?
The preview gap is the loss of visual context that editorial teams experience when moving from a WYSIWYG (what you see is what you get) environment to a structured content interface, and it is the most immediate friction point in any headless CMS migration.
Authors who previously built pages visually are now filling in form fields and trusting that a front-end will render them correctly. The shift from “building a page” to “managing a content object” takes adjustment, and “once teams adapt, the structured approach tends to produce more consistent, reusable content.” The problem is what happens before they adapt.
What happens is that authors create workarounds. They paste formatted content into rich text fields, breaking the structured model. They submit tickets to developers asking “what will this look like?” multiple times per week. They maintain shadow documents in Google Docs so they can see their work in context. Every workaround is a governance failure — content that exists outside the system, formatting that undermines the content model, and developer time consumed by preview requests instead of feature development.
The planning that pays off includes building live preview environments for as many content sources as possible. This development work typically gets deprioritized because it is not user-facing, but it determines the success of the new system. As one migration guide puts it, headless platforms deliver excellent editorial experiences “when configured correctly — visual editing, live preview, flexible page-building, role-based permissions. But that configuration is work, it doesn’t happen by default.” Budget for it, build it first, and do not launch editorial access without it.
What Is the Ownership Vacuum?
The ownership vacuum is what happens when structured content crosses departmental boundaries without clear governance over who maintains the content model, who approves changes to shared components, and who is accountable when content is reused in a context the original author never intended.
In a traditional CMS, the marketing team owns the marketing pages, the product team owns product pages, etc. Structured content breaks this model deliberately — a product description created once might appear on the website, in a mobile app, in an email campaign, and through a chatbot simultaneously. But governance complexity affects 41% of CaaS adopters, and multi-team collaboration across 6 to 10 departments increases governance overhead by 27%.
Questions seldom asked include:
- When the compliance team changes a regulatory disclaimer, who is responsible for verifying that the change renders correctly across every channel consuming that content object?
- When marketing adds a field to the product content type, who assesses the downstream impact on the mobile app and the support knowledge base?
We have seen organizations discover these questions six months post-launch, usually during a content audit that reveals inconsistencies no one can trace. In regulated industries — healthcare, financial services, higher education — those inconsistencies are compliance risks.
Knowing these pitfalls ahead of time can lead to the establishment of a content model governance board before migration begins. A small, cross-functional group (typically 3 to 5 people spanning content strategy, development, and compliance) owns the content model as a shared organizational asset. They approve changes to content types, evaluate reuse implications, and maintain a living inventory of where shared content objects appear. This role does not exist in traditional CMS organizations because it’s not needed. But in structured content environments, it is absolutely necessary.
Why Does the Training Deficit Compound Everything?
Because organizations allocate 90% of their transformation budgets to technology and implementation, and only 10% to change management — the part that determines whether anyone actually uses the system they built.
Training requirements for CaaS implementations average 14 to 18 weeks, the elapsed time from initial exposure to genuine editorial fluency. This training creates the confidence for authors to create, structure, and publish content without reverting to old habits or filing developer tickets. Most implementation budgets account for a one-day training session and a knowledge base article. The gap between that and actual fluency is where adoption dies.
The compounding effect of the training deficit makes this particularly damaging. Undertrained authors hit the preview gap and panic. Without clear governance ownership, there is no one to answer their questions authoritatively. They build workarounds. Those workarounds corrupt the content model. The corrupted content model undermines the case for structured content. Stakeholders lose confidence. The transformation stalls.
BCG’s study of 850+ companies found that only 35% of digital transformations meet their value targets globally. The failure rate is a change management problem that looks like a core problem with the technology itself.
To avoid this failure spiral, structure editorial onboarding as a phased engagement, not a one-and-done event. In our implementations, we start with a pilot group of 3 to 5 authors working with the system while the front-end is still being built. They surface friction points the development addresses in real-time. When the broader editorial team is onboarded, the common pain points have been resolved, and the pilot group serves as advocates who can answer questions and support their peers. This approach adds little cost and dramatically improves adoption velocity.
What Should Organizations Do Before Starting a Structured Content Migration?
Treat governance design as a foundation to build a successful digital transformation:
- Audit your editorial workflows as they actually operate. Map who creates content, who reviews it, who approves it, and where informal workarounds exist. As one migration planning guide advises, most publishing workflows “are often based on legacy systems, informal approvals, or staff availability. The result? Delays, missed steps, and content that never quite gets finished.” Your structured content governance must account for the real workflow, not the theoretical one.
- Define content model ownership before selecting a platform. Determine who will own the content model as an organizational asset, who can request changes, and what the approval process looks like. This governance structure should be platform-agnostic — it is an organizational decision, not a technical one. We have helped clients build this through our roadmapping and strategy engagements, and it consistently reduces mid-project governance confusion.
- Budget for editorial experience parity. If your authors currently have WYSIWYG editing, live preview, and visual page building, do not assume they will accept a simpler and more limiting form-based interface. Calculate the development effort required to provide contextual preview in your new architecture and include it in the implementation scope, not as a phase-two enhancement. Phase two rarely arrives before editorial frustration does.
Wrap Up
The CaaS pitch is not wrong. Structured content distribution is the right architecture for organizations publishing across multiple channels, and it is increasingly the right architecture for AI readiness — structured data is what AI systems consume most effectively. But the promise underestimates the organizational effort to make it successful.
Technology is the easy part. Governance, training, and editorial adoption are harder, and that is where implementations succeed or fail.
We have built these systems on Contentful, Drupal, and composable architectures for organizations in regulated industries where getting content wrong has real consequences. The lesson we keep relearning is the same one: start with the team, not the platform.
Bill Gates wrote “Content is King” back in 1996. He was right for about thirty years. On the open web, the winners were the ones who could produce, distribute, and monetize content at scale. That era shaped how we built digital products, how we organized marketing teams, and how we thought about content platforms.
That era is getting a new chapter.
When content becomes context
In the age of agents, content is context. It’s the raw material an AI uses to answer a customer’s question, draft a proposal, summarize a policy, or make a decision on behalf of your business.
If your context is a mess, your agent is a mess. Garbage in, confident-sounding garbage out.
For organizations in healthcare, higher education, and associations (industries where we work every day) that governance layer isn’t a nice-to-have. A health system deploying an agent to answer patient questions needs to know which clinical protocol is current, who approved it, and what the agent is and isn’t allowed to cite. An association managing member benefits can’t afford an agent that surfaces a two-year-old policy document as current guidance. And it’s not just the regulated organizations themselves. The enterprise technology companies that serve these industries, the SaaS platforms, the data providers, the system integrators, face the same challenge: if the content powering their products isn’t structured and governed, the agents built on top of it will inherit every gap. The stakes in regulated industries make the content-as-context problem concrete and urgent, but the same dynamics show up everywhere brand, voice, and accuracy matter: retail pricing, financial disclosures, B2B product specifications, public sector policy. Different risk profiles, same fundamental problem.
This isn’t theoretical. Gartner predicts that 40% of enterprise applications will include task-specific AI agents by the end of 2026, up from less than 5% in 2025. The shift is already moving from prediction to product.
The platforms we work with every day show the movement clearly. The Drupal AI Initiative launched last June and hit $1 million in funding within five months, with the Drupal AI and AI Agents modules reaching production-ready status in October 2025. Acquia built on that foundation with Acquia Source, shipping three AI agents for its Drupal-powered SaaS CMS in December. Contentful open-sourced its MCP server and has been publishing active guidance on agentic content operations. These aren’t experiments. They’re shipping.
Across the category, the pattern is broad. Contentstack launched Agent OS in September 2025 and introduced what it calls the “Context Economy” as its positioning. Kontent.ai shipped what it calls an Agentic CMS the following month. The Model Context Protocol that Anthropic introduced in late 2024 has become the connective tissue, adopted by OpenAI, Google DeepMind, and most of the CMS world.
The platforms are ready. The question is whether your content is.
What agents actually need
An agent doesn’t want a rendered web page. It wants structured, canonical, permissioned, versioned truth. That means:
- Structure so the agent can reason over content rather than scrape through marketing copy
- Versioning so it knows which policy, price, or product spec is current
- Permissions so the agent answering a customer question can’t pull from an internal-only HR doc
- Freshness signals so stale content doesn’t get treated as authoritative
- Governance so legal, brand, and compliance can trust what the agent says on their behalf
That’s the same job a mature content platform has been doing for years, just pointed at a new kind of consumer.
We’ve seen this movie before
Every channel shift exposes whether your content was ever really structured to begin with. CD-ROM, then the web, then mobile, now agents. Each one forces organizations to untangle content from presentation. Headless CMS platforms like Drupal, Contentful, Sanity, and Strapi won that argument. Content as structured data, delivered via API, rendered wherever you need it.
Agents are the most demanding channel yet. They don’t just display your content. They consume it, reason over it, and then take action. If your content is trapped inside HTML blobs or buried in PDFs that no one’s touched since 2021, it’s not ready to be context. Structure is the whole game now.
Where context lives today
Right now, company context is scattered across:
- Websites and headless CMS platforms
- GitHub repos full of markdown
- Confluence, Notion, SharePoint, Google Drive
- Salesforce, HubSpot, and a dozen other systems of record
- PDFs, Slack threads, and somebody’s laptop
Some of these are built for governance. Most aren’t. GitHub is hands-down great for technical content and version control, but marketing and legal teams aren’t opening pull requests to update a pricing page. Notion is excellent for collaboration, weak on structured content models and role-based delivery. Every organization I talk to has some version of this scatter, and it’s about to become a much bigger problem.
The rise of the Context Management System
The old acronym still works. CMS. New job.
Headless CMS platforms have quietly solved about 70% of what agents need. Structured content models. API-first delivery. Editorial workflows. Roles and permissions. Versioning. Audit trails. What they’re adding now is the connective tissue. Acquia is embedding AI agents directly into Drupal-powered workflows through Acquia Source, and Contentful has open-sourced its MCP server to let agents take action on content operations. Across the rest of the category, Sanity launched its Content Agent in January 2026, and Storyblok, Brightspot, and dotCMS have released MCP servers of their own. MCP servers, vector indexing, semantic metadata, agent-optimized delivery endpoints. That’s a much smaller leap than building the whole governance layer from scratch.
The “just throw it all in a vector database” approach has real merit as a retrieval layer. Retrieval is one job. Governance is a different one: who owns canonical truth, who approved the content, when it expires, and who’s allowed to see it. That’s always been the CMS job. It matters more now, not less.
For teams working on Drupal, Contentful, or Acquia Source, this is encouraging. The architectural decisions those platforms made years ago (structured data, granular revisioning, API-first design) turn out to be exactly what AI agents need. Your investment in content architecture is paying off in ways you didn’t plan for. Call it a head start.
What to do about it
If you’re building agentic products, or planning to, the content question is the quiet one that will bite you later. This is the work we’re spending most of our time on with clients right now. A few forward moves:
- Audit where your content actually lives and who owns it. You will be surprised.
- Pick a source of truth for each category of content. Don’t let five systems claim the same ground.
- Get your structured content models right. If your content is trapped inside HTML, it isn’t ready to be context.
- Build the governance layer before you need it. Versioning, permissions, approval workflows. Your legal team will thank you. So will your agent.
- Connect your CMS to your agents via MCP or equivalent. This is how context flows. Do it early.
Content was king when the battle was for attention. Context is king now that the battle is for correctness. Agents are only as good as the material you feed them, and that material has to be managed with the same rigor we’ve applied to code, to data, and yes, to content itself.
The organizations that treat content governance as infrastructure, not a cleanup project, will be the ones whose agents are trustworthy from day one. That window is shorter than it looks.
As direct website traffic decreases and LLMs slurp up text from multiple sources to mix together and redistribute to users, it has never been more important to maintain high-quality online content. A ROT analysis — which stands for Redundant, Obsolete, Trivial — is a framework through which we can evaluate site content to improve it for usability, SEO, retrieval, and GEO.
This is a flexible exercise that can apply to a variety of digital properties: web pages, PDFs, intranets, social media pages, call center databases, support knowledgebases… Anywhere that you, as an organization, are speaking to your audience, you have an opportunity to share knowledge, build trust, and solidify your brand image.
Similarly, ROTten content can mislead users, seed doubt, and damage your reputation.
When you use a ROT analysis to kickstart a content clean-up project, you’re ensuring that users and bots alike find only your latest, clearest, most accurate and relevant information. When done properly, it can even set up your team for better content production and management in the future.
How Oomph Approaches Content ROT Analyses
Every ROT analysis looks a little different depending on the industry, content, and what a particular audience needs.
Make a Plan
Before jumping into dashboards and spreadsheets, we start with a conversation. With any project, we need to understand what problems your organization needs to solve: What’s important to you and your users? Where are you struggling? This is our chance to understand the why behind your content.
As we learn more about what you need, we’ll define what ROT is for your organization. What existing policies do you have in place around archiving old or outdated content? If you don’t have policies, what makes sense for you? What key user journeys should the analysis focus on? We’ll answer these questions and more to make sure we’re going into the analysis with a clear vision of what your content should look like so we can see where it’s missing the mark.
Find the ROT
Let’s get into what ROT looks like specifically and where we look for it.
Redundant means the content communicates information in more than one place. This can result in an inefficient information architecture and messy user paths. There are times duplicate content can be helpful, like when separate task flows require some of the same information. That’s why it’s important to know upfront what journeys are most important to prioritize. In these cases, when the same content shows up in multiple places across a website or app, it’s important to have a method for keeping all content in sync. If it’s possible to edit this content in a single place while distributing it across multiple pages, that can be a great method for maintaining a single source of truth.
Redundant might also refer to several articles written over time that deal with the same topics in similar ways. This can result in the newest content on the topic having its SEO/GEO cannibalized by older content on the same topic. Users might more easily find older content when you want them to find the latest.
Obsolete content includes outdated information, language, and (probably broken) links. This type of ROT is especially damaging when it’s related to products, services, or something users are trying to take action on. It’s important to keep in mind your entire digital landscape; Maybe you’ve updated the content on your main service page, but did you remember to update automated emails, support articles, and meta descriptions? What pages aren’t built directly into a user flow but can still be found by Google?
Consider whether it makes sense to archive or unpublish old content, like past news and events. And consider your audience: Is there a reason users would be looking for a historical record, and is that need strong enough to justify keeping it available? If you do choose to keep outdated information published, make sure that it’s clear to users that the content is old and consider providing a link to the latest version.
Trivial content can be harder to define and is highly subjective based on the organization. This might look like “fluff” pieces shared for the sake of SEO or maintaining a publishing schedule, or excessive marketing language that ultimately doesn’t serve you or your users. It might be low-traffic fine print details that apply to a specific audience who typically finds it another way. Maybe it’s content that is related to but outside of your core business function. You’ll need to make some decisions about what is important to you.
To find ROT, we’ll use a variety of collection and measurement tools. SortSite, Screaming Frog, and Siteimprove can locate broken links, orphaned pages, and other SEO issues. Google Analytics, Hotjar, Contentsquare, and MS Clarity can show common user flows and help identify trivial content. Data from these tools can also prioritize the analysis by surfacing what content is most important to users. If a page gets a lot of traffic, we know that it needs to be clear, up-to-date, and accurate. If a page isn’t visited much, we need to ask whether it should be more highly trafficked, consolidated with higher performing content, or removed.
Deliverables and Next Steps
After all this sorting and evaluating, you might be wondering what you’ll tangibly get out of the process. We know content teams are busy, and going through a review can feel like adding more work to the pile. How can we help prioritize meaningful progress here?
The big outcome is one of my personal favorites: a clean, annotated, actionable spreadsheet. Specifically, we’ll put together an audit of your content with links, page titles, notes on whether the content falls into any of the three ROT categories, and what to do about it: keep, modify, combine, or delete. Depending on the tools your content team uses or what you are willing to subscribe to, we might prepare dashboards and reports directly within an app that your team can use as an ongoing progress tracker. Wherever this list of to-do’s lives, we’ll help you prioritize it so you can start ticking off the most crucial items. Depending on what we decided in early scoping agreements, we can even help work through some high-impact issues, like bulk deleting content, suggesting rewrites, and fixing broken links.
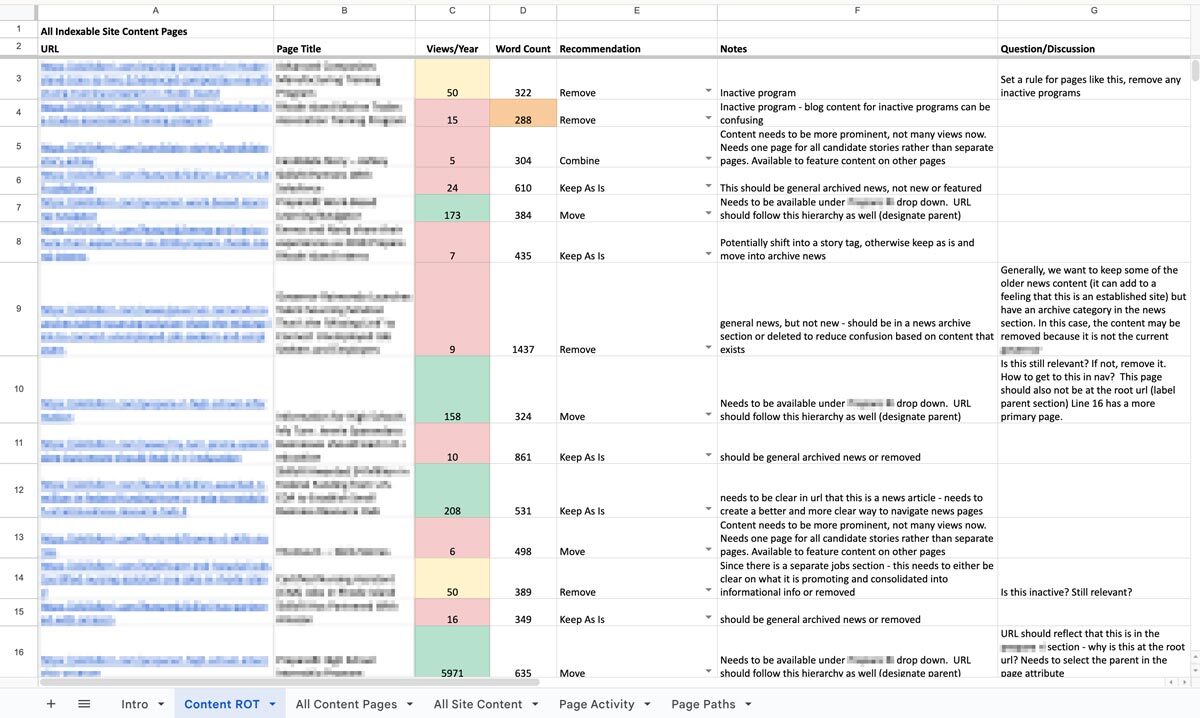
We can also set up an ongoing content hygiene plan. While a dedicated content ROT analysis is a great way to identify and work through issues, an effective content plan should prevent ROT as much as possible and reduce the need for a large effort in the future. This might involve setting up policies, practices, and tools to guide future content management. We’ll help you find ways to see the bigger picture when updating or developing new content to make sure all pieces are accounted for. And when ROT falls through the cracks, you’ll have a plan to regularly review site content, setting ahead of time the when, what, and who.
One Piece in the Puzzle of Strong Content
As we continue to inspect the quality of your website and other digital properties, we can use this ROT analysis as a jumping off point. The initial audit may lead directly into a deeper content audit to evaluate URL paths, heading usage, performance metrics, reading level, and more. As we consider reworking, combining, and cutting entire pages, we may find the need to restructure your information architecture and taxonomy structures, in part or in whole, informed by research exercises like card sorts and tree tests. Depending on what we’ve found in the existing content and how it needs to change, we might suggest changes to your content model, adding, modifying, or removing content types and the relationships between them.
A content ROT analysis is a flexible and fruitful way to take a fresh look at your content ecosystem. If you need help getting started, let us know. We’d love to dig in with you!
Compliance with the California Consumer Privacy Act (CCPA), as amended by the California Privacy Rights Act (CPRA), is a mandatory legal obligation for covered businesses, with significantly increased financial and operational risks starting in 2025.
The Critical Risk: Escalating Fines and Penalties
As of January 1, 2025, the California Privacy Protection Agency (CPPA) increased monetary thresholds and fines to align with the Consumer Price Index.
- Civil Penalties: Businesses face up to $2,663 per unintentional violation and up to $7,988 per intentional violation or those involving minors.
- No Total Cap: Because each individual consumer affected by a breach or non-compliant practice can count as a separate violation, total fines for large-scale data incidents can quickly reach millions of dollars.
- Private Right of Action: Consumers can sue for statutory damages between $107 and $799 per incident (or actual damages) following a data breach involving unencrypted personal data.
Key Deadlines and New Requirements (2026–2028)
Regulators have moved from a passive to an active enforcement model, removing the mandatory “grace period” for fixing violations before penalties are applied.
- Mandatory Risk Assessments (Effective Jan 1, 2026): Businesses must conduct risk assessments for “significant risk” processing, such as selling/sharing personal data or using sensitive information.
- Automated Decisionmaking (ADMT): New requirements for technologies that replace human decision-making (e.g., for credit or employment) go into effect, with a compliance deadline of January 1, 2027.
- Mandatory Reporting: Organizations must begin reporting their risk assessment activities to the CPPA by April 1, 2028.
Does This Apply to My Business?
A for-profit business must comply if it does business in California and meets any of the following:
- Gross annual revenue exceeds $26.625 million (updated for 2025).
- Buys, sells, or shares the personal information of 100,000 or more California residents or households.
- Derives 50% or more of its annual revenue from selling or sharing personal data.
Operational Impact of Non-Compliance
Beyond fines, non-compliance can lead to court-ordered injunctions, mandatory regular audits, and the required deletion of valuable data assets. It also risks significant reputational damage and customer churn, as modern consumers increasingly prioritize data security when choosing where to spend.
Is your website ready for California’s evolving privacy standards? Non-compliance isn’t just a legal risk — it’s a business one that can result in millions in fines, mandatory audits, and lasting reputational damage. Our team helps organizations like yours navigate complex regulatory requirements with confidence, so you can focus on what matters most. Talk to our team today.
Selecting a content management system in healthcare is no longer a purely technical decision. In today’s environment, a CMS directly impacts compliance, accessibility, speed to publish, and ultimately, trust. Healthcare organizations are under growing pressure to deliver accurate, timely information across multiple digital channels, while meeting strict regulatory and accessibility requirements. The CMS at the center of that effort needs to support far more than page updates.
Why Healthcare CMS Decisions Are Uniquely Complex
Healthcare websites serve a wide range of audiences, from patients and caregivers to providers, partners, and regulators. Content must be clear, accurate, and easy to update—often by multiple teams—without introducing risk.
At the same time, healthcare organizations face constraints that many other industries don’t. Accessibility standards, privacy expectations, and governance requirements are non-negotiable.
A CMS that lacks flexibility or control quickly becomes a bottleneck.
“The healthcare content management system market is projected to grow to over $61 billion by 2031, underscoring how healthcare organizations are prioritizing modern, scalable digital platforms to support compliance, multi-channel delivery, and governance.”
According to Mordor Intelligence
What Healthcare Teams Should Prioritize
- A healthcare CMS must support strong governance without slowing teams down. Role-based permissions, approval workflows, and auditability are essential to ensure content accuracy and accountability.
- Accessibility also needs to be built into everyday publishing, not treated as an afterthought. The CMS should make it easy for teams to maintain WCAG-compliant content as sites evolve.
- Equally important is the ability to scale across channels. Healthcare content increasingly lives beyond the website—patient portals, mobile apps, email, and emerging digital touchpoints all require consistency. Managing this content from a single system reduces duplication and risk.
Flexibility Without Compromising Security
Healthcare organizations often rely on complex digital ecosystems, including EHRs, portals, analytics tools, and consent platforms. A modern CMS should integrate cleanly with these systems rather than trying to replace them.
Flexibility matters, but not at the expense of security. The right CMS supports modular integration while keeping sensitive data protected and clearly separated from content operations.
Planning For Change, Not Just Launch
CMS selection shouldn’t be based solely on current needs. Healthcare regulations, digital expectations, and technologies continue to evolve. The most effective platforms are designed to adapt without requiring frequent replatforming.
This means supporting incremental improvements, phased rollouts, and long-term scalability—so teams can modernize at a pace that aligns with organizational priorities.
The Role Of Modern, Composable CMS Platforms
Composable CMS platforms are gaining traction in healthcare because they treat content as structured data rather than static pages. This approach supports reuse, consistency, and omnichannel delivery while maintaining governance.
For healthcare teams, this translates into faster publishing, fewer bottlenecks, and greater confidence in content accuracy without sacrificing compliance.
What This Means For Healthcare Teams
Healthcare CMS selection is about more than choosing a tool. It’s about enabling teams to communicate clearly, operate efficiently, and adapt responsibly in a complex digital landscape.
Organizations that prioritize governance, accessibility, and flexibility position themselves to deliver trusted digital experiences today and in the years ahead.
Ready to Evaluate Your Healthcare CMS? Our team helps healthcare organizations navigate complex CMS decisions with a focus on governance, accessibility, and long-term scalability. Let’s talk about what the right platform looks like for your organization.
To avoid significant financial penalties, which increased on January 1, 2025 to up to $7,988 per intentional violation, your website must function as a compliant interface for consumer privacy rights. Use this checklist to assess your current standing.
1. Mandatory Homepage Links
- “Do Not Sell or Share My Personal Information”: A clear and conspicuous link must be in the footer or header if you sell or share data for targeted advertising. This includes:
- Retargeting Ads: Uploading your email list to Facebook (Meta), Google, or LinkedIn to show ads to those specific users or to find “Lookalike” audiences.
- Data Brokerage: Selling your email list to another company or “renting” it out for their own marketing.
- Third-Party Analytics: Sharing email-linked identifiers with ad networks that track users across multiple unrelated websites.
- “Limit the Use of My Sensitive Personal Information”: Required if you collect sensitive data (e.g., precise geolocation, health info, or race) for purposes beyond providing the core service.
- Alternative Option: You may use a single, combined link labeled “Your Privacy Choices” or “Your California Privacy Choices” that includes an icon if desired.
2. Automated Privacy Signals (Global Privacy Control)
- GPC Detection: Your website must automatically detect and honor “Global Privacy Control” (GPC) signals from user browsers (e.g., Brave, DuckDuckGo) as a valid opt-out request.
- Status Confirmation: As of January 1, 2026, you must display a clear confirmation to the user, such as a message stating “Opt-Out Request Honored,” when a GPC signal is detected.
3. Notice at Collection
- Timely Disclosure: You must provide a notice at or before the point of collection (e.g., on a sign-up form or via a cookie banner).
- Content Requirements: The notice must list categories of personal and sensitive info collected, the specific purpose for each, and how long each category will be retained.
4. Consumer Rights Intake (DSARs)
- Dual Methods: You must provide at least two designated methods for submitting requests (e.g., a web form and a toll-free number).
- Verification: Establish a process to verify a consumer’s identity without requiring them to create a new account solely for the request.
5. Technical & Policy Maintenance
- Accessibility: All notices must follow Web Content Accessibility Guidelines (WCAG) and be available in every language in which you conduct business.
- Annual Update: The online Privacy Policy must be reviewed and updated at least once every 12 months.
- No “Dark Patterns”: Ensure the user interface is symmetrical; for example, it should not be significantly harder to “Opt-Out” than it is to “Opt-In”.
Is your website one missing link or undetected signal away from a costly CCPA violation? Oomph’s team can walk you through a compliance audit, identify gaps in your current setup, and help you implement the technical and content updates needed to protect your organization. Get in touch with us today to book your CCPA compliance call.
In 2026, website accessibility has shifted from a “best practice” to a strictly codified legal requirement. New federal and state regulations have eliminated previous ambiguities, making WCAG 2.1 Level AA the mandatory technical standard for digital content.
1. The 2026 Enforcement Cliff
The U.S. Department of Justice (DOJ) finalized a rule under Title II of the ADA that sets a firm compliance deadline for many entities:
- April 24, 2026: Deadline for public entities (and many private partners) serving populations of 50,000 or more to achieve full WCAG 2.1 Level AA conformance.
- April 26, 2027: Deadline for smaller entities.
- Private Sector Impact: While the DOJ rule focuses on public entities, it solidifies WCAG 2.1 AA as the de-facto legal standard for private businesses in Title III lawsuits, which saw a 102% increase in recent years.
2. Why WCAG 2.1 Level AA?
Unlike older versions, WCAG 2.1 includes 17 additional criteria specifically designed for mobile accessibility and users with cognitive disabilities. Compliance is measured by the “POUR” Principles:
- Perceivable: Users must be able to see or hear content (e.g., Alt-Text for images, captions for video).
- Operable: The site must work without a mouse (e.g., Keyboard-only navigation, no keyboard traps).
- Understandable: Content must be predictable with clear error messaging on forms.
- Robust: Code must be “clean” enough to work with all current and future assistive technologies, like screen readers.
3. Critical 2026 Compliance Risks
- No “Grandfathering” for New Content: Any digital asset (PDFs, videos, or web pages) posted after April 2026 must be compliant from day one.
- Vendor Liability: Business owners are legally responsible for their website’s accessibility, even if they use third-party platforms or templates.
- Inadequacy of “Overlay” Widgets: The DOJ has clarified that automated widgets or “overlays” alone cannot guarantee ADA compliance; true accessibility requires fixing the underlying code.
- California-Specific Penalties: Under California’s Unruh Act, businesses can face statutory damages of $4,000+ per violation in addition to federal ADA settlements.
4. Future-Proofing: Looking Toward WCAG 3.0
While WCAG 2.1/2.2 is the current law, WCAG 3.0 is in development (expected no earlier than 2028). It will move from a pass/fail model to a Bronze, Silver, and Gold scoring system. Achieving WCAG 2.1 Level AA now effectively places an organization at the “Bronze” level, providing a solid foundation for future shifts.
Is your website ready for the April 2026 deadline? Achieving WCAG 2.1 Level AA compliance requires more than a quick fix — it means addressing the underlying code, auditing every digital asset, and building accessibility into your process from the ground up. Whether you’re starting an audit, planning remediation, or building something new, get in touch with our team to start the conversation.
Contentful is no longer just an alternative CMS—it’s become a foundational platform for organizations navigating complexity, regulation, and rapid digital change. In 2026, the question isn’t what is Contentful? It’s why are so many organizations rebuilding their digital ecosystems around it? The answer lies in how digital experiences are built, managed, and scaled today.
Contentful Is Built for Systems, Not Pages
Traditional CMS platforms were designed around pages and templates. That model breaks down when content needs to move faster, live in more places, and remain consistent across teams and channels.
Contentful takes a different approach. It treats content as structured data, not static pages. That means teams create content once and deliver it anywhere—websites, apps, portals, email, or future channels that don’t yet exist.
In 2026, this isn’t a “nice to have.” It’s how modern digital platforms operate.
Composable Architecture Is Now the Default
Composable architecture has moved from trend to standard. Organizations want the freedom to choose best-in-class tools without being locked into monolithic platforms.
Contentful fits cleanly into this model. It integrates with design systems, analytics platforms, personalization tools, consent managers, and AI services through APIs—without forcing teams into rigid workflows.
This flexibility allows organizations to evolve their stack over time instead of rebuilding every few years.
AI Depends on Structured Content
AI-driven experiences are only as good as the content behind them. In 2026, organizations are using AI to support personalization, search, localization, content optimization, and automation.
Contentful’s structured content model makes this possible. Clean, well-defined content enables AI tools to understand, reuse, and adapt content accurately—without introducing risk or inconsistency.
For teams exploring AI responsibly, Contentful provides the infrastructure needed to scale with confidence.
Governance and Compliance Are Built In, Not Bolted On
For regulated and mission-driven organizations, governance isn’t optional. Publishing controls, audit trails, permissions, and review workflows are essential.
Contentful supports these needs at scale. Teams can define roles, control who edits or publishes content, and maintain visibility into changes across environments. This level of governance is critical in industries like healthcare, legal, finance, and the public sector.
In 2026, compliance isn’t something teams add later—it’s designed into the platform from day one.
Marketing and Development Work Better Together
One of Contentful’s biggest advantages is how it aligns marketing and engineering teams. Developers maintain design systems and integrations. Content teams manage content without breaking layouts or workflows.
This separation of concerns reduces friction, speeds up delivery, and minimizes production errors—especially as digital ecosystems grow more complex.
Ready to explore what Contentful could do for your organization? Whether you’re evaluating platforms, planning a migration, or looking to optimize your current setup, Oomph can help you build a content infrastructure designed for the long term. Let’s talk about your next move.

Why Organizations Move to Contentful Now
Organizations typically migrate to Contentful when legacy systems start holding them back. Common triggers include:
- Slow publishing workflows
- Heavy developer dependency
- Difficulty scaling across channels
- Growing compliance requirements
- The need to support AI and personalization
In 2026, Contentful isn’t chosen because it’s new. It’s chosen because it’s resilient.
For organizations new to the platform, getting started doesn’t have to mean a complete rebuild. Oomph’s Contentful Kickstart Package helps teams move from decision to deployment with a structured, low-risk approach—giving you the foundation to scale as your needs evolve.
The Takeaway
Contentful has evolved alongside the modern digital landscape. It’s not just a CMS—it’s a content platform designed for scale, governance, and change.
For organizations planning beyond their next website launch and toward long-term digital maturity, Contentful provides the flexibility and confidence needed to move forward.
Ready to explore what Contentful could do for your organization? Whether you’re evaluating platforms, planning a migration, or looking to optimize your current setup, Oomph can help you build a content infrastructure designed for the long term. Let’s talk about your next move.
For many organizations, privacy regulations like GDPR and CCPA seem like distant legal concerns rather than operational priorities. In practice, however, websites serve as the primary point of data collection—making compliance far more relevant than most teams assume. If your site collects user data in any form, privacy compliance isn’t optional.
Understanding When GDPR and CCPA Apply
GDPR governs the collection of personal data from users in the European Union, while CCPA applies to personal data collected from California residents.
Crucially, these regulations are triggered by user location, not company headquarters. A U.S.-based organization serving a global audience may be subject to both frameworks.
Why Websites Are at the Center of Compliance
Most modern websites collect data through multiple channels:
- Contact and intake forms
- Newsletter subscriptions
- Analytics and tracking tools
- Cookies and personalization technologies
- Third-party embeds and integrations
Each of these collection points creates compliance obligations around consent, transparency, and user control.
Moving Beyond Cookie Banners
Meaningful compliance extends well beyond footer disclaimers. Effective privacy management requires:
- Clear consent and opt-out mechanisms
- Transparent communication about data usage
- The ability to update policies efficiently
- Controlled publishing workflows
- Comprehensive auditability for content and data modifications
Legacy CMS platforms frequently lack the flexibility and governance capabilities needed to meet these requirements.
The Role of Your CMS in Privacy Compliance
Your content management system is instrumental in supporting privacy obligations. A modern, composable CMS enables organizations to:
- Decouple content from data logic
- Integrate consent and privacy tools seamlessly
- Manage access and publishing permissions effectively
- Deploy compliance updates across all channels instantly
- Minimize risk by limiting unnecessary data exposure
For regulated and mission-driven organizations, CMS limitations can translate directly into compliance vulnerabilities.
The Cost of Non-Compliance
While regulatory penalties are a concern, the greater risk lies in eroding user trust.
Today’s users expect transparency and control over their personal information. Organizations unable to deliver on these expectations risk damaging their reputation with customers, donors, and partners.
Final Thoughts
GDPR and CCPA represent more than legal obligations—they present fundamental digital experience challenges. Websites built on flexible, compliance-ready platforms are better positioned to adapt as privacy expectations continue to evolve.
In today’s environment, privacy compliance shouldn’t be viewed as a constraint. It’s an essential component of delivering a modern, trustworthy digital experience.
Need help ensuring your website meets modern privacy standards? Our team specializes in building compliance-ready digital platforms that protect your users and your organization. Let’s discuss your requirements.
In recent months, Generative Engine Optimization (GEO) has been gaining attention, often positioned as the next evolution beyond traditional Search Engine Optimization (SEO). For some clients, this presents an exciting opportunity to rethink and restructure their digital content. For others, it can feel overwhelming, raising more questions than answers. As AI-powered search tools like ChatGPT, Perplexity, and Gemini change how people discover content online, clients increasingly ask: What is GEO, and how can we prepare our sites for it?
The following handy Q&A guide aims to demystify Generative Engine Optimization (GEO), explain why it matters, and provide practical steps your team can take to get started.
Q: What is GEO and how is it different from SEO?
A: GEO stands for Generative Engine Optimization. While SEO (Search Engine Optimization) focuses on getting your content to rank in traditional search engines like Google (via keywords, backlinks, and site performance), GEO focuses on getting your content mentioned, referenced, summarized, or cited in AI-generated answers from tools like ChatGPT, Gemini, and Perplexity.
Think of SEO as getting your content listed, whereas GEO is about making your brand and its content the answer.
Q: Why should my organization care about GEO?
A: AI platforms are rapidly becoming the first stop for users looking for answers, especially younger audiences and professionals. If an answer appears via Gemini on the top of a Google search, fewer people may scroll further down the page to look for other sources. They got the answer they needed from just one search. If your content isn’t optimized for these tools, you’re missing out on certain traffic data, visibility, and an opportunity to build trust.
In 2026, ChatGPT alone sees over 4.5 billion visits per month, and Perplexity handles nearly 500 million monthly queries.
Q: How is GEO impacting my site’s analytics?
A: Likely a lot. Generative engines often summarize content without requiring a click. That means you may see fewer impressions and clicks, even if your content is powering the AI’s answer. Most websites are seeing direct traffic declining across the board. With that said, users who do click through to sites are often engaging more deeply, leading to longer session durations and higher conversion rates.
Because of this, it’s crucial to learn these new patterns and recognize them within your site’s analytics by setting up new reports.
Q: How do AI engines choose which content to cite?
A: AI tools evaluate a number of factors, with the most important being:
- Authority: Are you a trusted source? Do you have backlinks, credentials, or media citations?
- Structure: Do you use schema markup, headings, and clear Q&A formatting?
- Freshness: Is your content updated regularly?
- Relevance: Does your content align with how users ask questions in natural language?
Each tool has its own algorithm, but clear, factual, structured content with recent updates from trusted sources performs best.
Q: What kind of content works best for GEO?
A: Content that answers questions directly, especially with a conversational tone, tends to work well. Additionally, you want your content to explain not just the what, but also the why and how, since generative engines often expand on user intent. Content structures that perform well for GEO include:
- Q&A sections
- “Top” or “Best” lists (Examples: Top Restaurants in Providence, Rhode Island or Best fall events in California)
- Evergreen guides that are updated annually
- Content that is organized for machines and humans (aka clear headings, mobile-friendly, structured data and metadata)
Q: How can we tell if our content is being featured in AI tools?
A: While most AI platforms don’t yet provide native analytics, you can track GEO success through:
- GA4 segmentation: Filter referral traffic by sources like chat.openai.com or perplexity.ai
- Landing page patterns: AI-driven referrals often land users deep into your site (e.g., specific blogs, not just the homepage)
- Google Search Console: Look for queries with high impressions but low click-through rates, these may indicate your content is being shown in AI Overviews
- Manual Testing: In an incognito window, search for the types of queries you want your site’s content to appear for and see what answers are returned. These might be simple questions like “What does [your organization] do?” or more in-depth research questions that your popular articles have addressed.
- Third Party Tools: As the field continues to develop, more third party tools are becoming available or adapting their analytics to provide insight into GEO success. SEMrush in particular is a tool that we recommend for clients interested in uncovering more data.
Q: Is there a way to make our site more “AI-friendly”?
A: Yes! Here are key GEO best practices:
- Use schema markup: Help AI models understand your content’s structure and intent. You can use schema.org to help guide you through improving your site’s markup.
- Write in a Q&A or conversational format: More people are asking full questions or prompts in ChatGPT—rather than just listing keywords. Match your content with how users phrase queries in AI tools.
- Optimize your About page: Make sure that your About page is thoughtfully written to answer who you are, what you do, and why. ChatGPT, for example, pulls from these pages to assess trustworthiness and authority.
- Refresh content: Update existing articles with new data and a clear structure (aka headings, bullets, FAQ sections, summaries). Note: You don’t need to create new URLs, just refresh the content to make sure it is relevant and current for today.
- Include citations and data points: Wherever possible, add data and sources. These increase your authority and credibility.
Q: Do we need to optimize differently for each AI tool?
A: The core strategies (trustworthiness, schema, natural language, performant) apply across all platforms, but there are nuances:
- Gemini: Heavily tied to Google’s ecosystem. Focus on crawlability and Core Web Vitals.
- Perplexity: Prefers cited, factual content and uses real-time web data.
- ChatGPT: Draws from authoritative sources like Wikipedia, news outlets, and Reddit. Strong personalization and structured content help here.
Q: Can we block AI tools from using our content?
A: Yes, but be thoughtful about what you are blocking. Adding a file like robots.txt can block AI crawlers, but doing so may reduce your visibility and lead to attribution from AI tools. It could also block legitimate crawlers and thus negatively impact both SEO and GEO, so be thoughtful about how you compose and format that file.
Note: If your brand has legal or content ownership concerns, we can help you assess what should or shouldn’t be available for AI training or citation.
Q: Do AI Tools honor authenticated access?
A: Yes, but remain mindful. Models like ChatGPT can’t “log in” or bypass authentication. If full research content is only available behind a user login, it won’t be included in training data or scraped summaries. But still pay attention to how content is displayed. If your research is behind a login or subscription paywall, ensure that:
- No full-text content is available to crawlers
- Abstracts or summaries shown publicly are limited in detail
Q: What is llms.txt and should I add it to my site?
A: llms.txt is a proposed convention for websites to provide a lightweight, machine- & human-readable summary (in Markdown) of the “important” parts of the site, to help large language models (LLMs) more easily crawl, interpret, and use content. More sites are starting to add it to their sites to help guide which pages AI should pay attention to. However, it is not yet a universally supported or enforced standard. Many LLMs or AI platforms do not currently yet automatically look for or honor llms.txt. As of now, you can think of it as a nice-to-have, not a requirement.
Q: How often should we update content for GEO?
A: Best practice recommends updating at least once a year for evergreen content. Prioritize updates for:
- Posts using phrases like “top,” “best,” or “recommended”
- Pages that receive seasonal traffic or include stats
- Key content that’s losing impressions or traffic in Google Search Console
Even simple updates like reordering information, adding new facts, or improving layout can go a long way with AI engines.
Q: Is GEO just another passing trend?
A: Not at all. GEO is a direct response to how AI is changing digital search and content discovery. Platforms like Google are rethinking their search experience through tools like Gemini, as more people turn to these tools for answers. GEO is how brands stay visible in this new AI landscape.
Q: What’s the first step we should take for GEO Optimization?
A: Start with a content and schema audit of your top-performing pages. From there, apply structured markup, rewrite headlines for clarity, add Q&A sections where applicable, and refresh key posts. A phased approach focused on high-value content will have the biggest immediate impact.
Need help figuring out what content to prioritize for GEO? Our team at Oomph can assess your current visibility and build a roadmap tailored to AI performance.
For more insights into GEO optimization, read…
- Everything You Should Know About Optimizing for GEO in 2026
- How LLMs Index Your Site — and How Accessibility Improves Their Answers and Your GEO
Generative Engine Optimization (GEO) is making organizations scramble — our clients have been asking “Are we ready for the new ways LLMs crawl, index, and return content to users? Does our site support evolving GEO best practices? What can we do to boost results and citations?”
Large language models (LLMs) and the services that power AI summaries don’t “think” like humans but they do perform similar actions. They seek content, split it into memorable chunks, and rank the chunks for trust and accuracy. If pages use semantic HTML, include facts and cite sources, and include structured metadata, AI crawlers and retrieval systems will find, store, and reproduce content accurately. That improves your chance of being cited correctly in AI overviews.
While GEO has disrupted the way people use search engines, the fundamentals of SEO and digital accessibility continue to be strong indicators of content performance in LLM search results. Making content understandable, usable, and memorable for humans also has benefits for LLMs and GEO.
How LLM systems (and AI-driven overviews) get their facts
Understanding how LLMs crawl, process, and retrieve web content helps us understand why semantic structure and accessibility best practices have a positive effect. When an AI system generates an answer that cites the web, several distinct back-end steps usually happen:
- Crawling — Bots visit URLs and download page content. Some crawlers execute javascript like a browser (Googlebot) while others prefer raw HTML and limit their rendering.
- Chunking — Large documents are split into small, logical “chunks” of paragraphs, sections, or other units. These chunks are the pieces that are later retrieved for an answer. How a page’s content is structured with headings, paragraphs, and lists determines the likely chunk boundaries for storage.
- Vectorization — Each chunk is then converted into a numeric vector that captures its semantic meaning. These embeddings live in a vector database and enable systems to find chunks quickly. The quality of the vector depends on the clarity of the chunk’s text.
- Indexing — Systems will store additional metadata (URL, title, headings, metadata) to filter and rank results. Structured data like schema metadata is especially valuable.
- Retrieval — A user asks a question or performs a search and the system retrieves the most semantically similar chunks via a vector search. It re-ranks those chunks using metadata and other signals and then composes its answer while citing sources (sometimes).
The Case for Human-Accessible Content
There are many more reasons why digital accessibility is simply the right thing to do. It turns out that in addition to boosting SEO, accessibility best practices help LLMs crawl, chunk, store, and retrieve content more accurately.
During retrieval, small errors like missing text, ambiguous links, or poor heading order can fail to expose the best chunks. Let’s dive into how this can happen and what common accessibility pitfalls contribute to the confusion.
For Content Teams — Authors, Writers, Editors

Lack of descriptive “alt” text
While some LLMs can employ machine-vision techniques to “see” images as a human would, descriptive alt text verifies what they are seeing and the context in which the image is relevant. The same best practices for describing images for people will help LLMs accurately understand the content.

Out-of-order heading structures
Similar to semantic HTML, headings provide a clear outline of a page. Machines (and screen readers!) use heading structure to understand hierarchy and context. When a heading level skips from an <h2> to an <h4>, an LLM may fail to determine the proper relationship between content chunks. During retrieval, the model’s understanding is dictated by the flawed structure, not the content’s intrinsic importance. (Source: research thesis PDF, “Investigating Large Language Models ability to evaluate heading-related accessibility barriers”)

Descriptive and unique links
All of the accessibility barriers surrounding poor link practices affect how LLMs evaluate their importance. Link text is a short textual signal that is vectorized to make proper retrieval possible. Vague link text like “Click here” or “Learn More” does not provide valuable signals. In fact, the same “Learn More” text multiple times on a page can dilute the signals for the URLs they point to.
Using the same link text for more than one destination URLs creates a knowledge conflict. Like people, an LLM is subject to “anchoring bias,” which means it is likely to overweight the first link it processes and underweight or ignore the second, since they both have the same text signal.
Example of the duplicate link problem: <a href=“[URL-A]”>Duplicate Link Text</a>, and then later in the same article, <a href=“[URL-B]”>Duplicate Link Text</a>. Conversely, when the same URL is used more than once on a page, the same link text should be repeated exactly.

Logical order and readable content
Simple, direct sentences (one fact per sentence) produce cleaner embeddings for LLM retrieval. Human accessibility best practices of plain language and clear structure are the same practices that improve chunking and indexing for LLMs
For Technical Teams — IT, Developers, Engineers
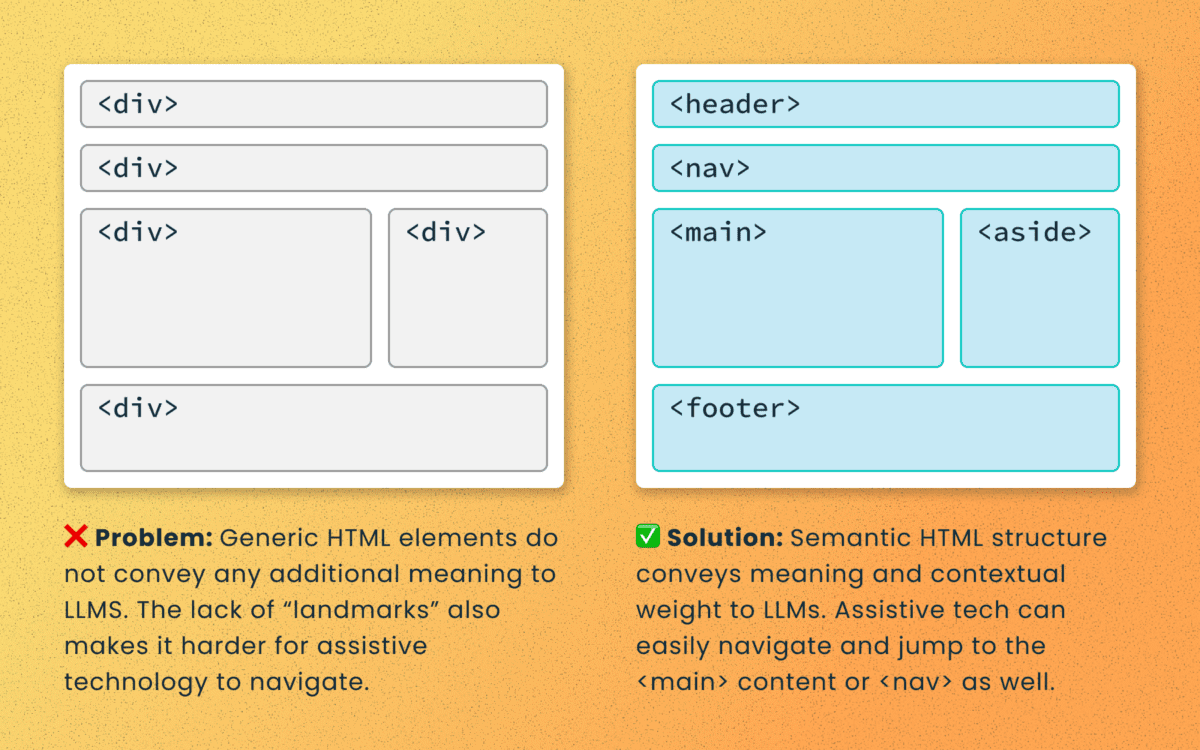
Poorly structured semantic HTML
Semantic elements (<article>, <nav>, <main>, <h1>, etc.) add context and suggest relative ranking weight. They make content boundaries explicit, which helps retrieval systems isolate your content from less important elements like ad slots or lists of related articles.

Lack of schema
This is technical and under the hood of your human-readable content. Machines love additional context and structured schema data is how facts are declared in code — product names, prices, event dates, authors, etc. Search engines have used schema for rich results and LLMs are no different. Right now, server-rendered schema data will guarantee the widest visibility, as not all crawlers execute client-side Javascript completely.
How to make accessibility even more actionable
The work of digital accessibility is often pushed to the bottom of the priority list. But once again, there are additional ways to frame this work as high value. While this work is beneficial for SEO, our recent research uncovers that it continues to be impactful in the new and evolving world of GEO.
If you need to frame an argument to those that control the investments of time and money, some talking points are:
- Accurate brand representation — Poor accessibility hides facts from LLMs. When customers ask an AI assistant for “best X for Y,” your content may not be shown — or worse, misrepresented. Fixing accessibility reduces brand risk and increases content authority.
- Engagement boost — Improvements that increase accurate citations and AI visibility can increase referral traffic, feature mentions, and lead quality. In a landscape where AI Answers are reducing click-through rates, keeping the traffic you have on your site for longer and building brand trust becomes vital.
- Increased exposure — Digital inclusion makes your content widely accessible to machines and the machines that assist humans. Think about a search engine as another human-assistive device, just like a keyboard or screen reader.
- Multi-pronged benefits — Accessibility improvement improves traditional SEO, can benefit mobile performance, and reduces the risks associated with accessibility compliance policies.
Staying steady in the storm
Let’s be clear — this summer was a “generative AI search freak out.” Content teams have scrambled to get smart about LLM-powered search quickly while search providers rolled out new tools and updates weekly. It’s been a tough ride in a rough sea of constant change.
To counter all that, know that the fundamentals are still strong. If your team has been using accessibility as a measure for content effectiveness and SEO discoverability, don’t stop now. If you haven’t yet started, this is one more reason to apply these principles tomorrow.
If you continue to have questions within this rapidly evolving landscape, talk to us about your questions around SEO, GEO, content strategy, and accessibility conformance. Ask about our training and documentation available for content teams.
Additional Reading
- AHREFs.com: Is SEO Dead? Real Data vs. Internet Hysteria
- SearchEngineJournal.com: How LLMs Interpret Content: How To Structure Information For AI Search
- InclusionHub.com: SEO and Web Accessibility: What You Need to Know (from 2020, but still relevant)
One question we frequently hear from clients, especially those managing web content, is “How can we implement accessibility best practices without breaking the bank or overwhelming our editorial team?”
It’s a valid concern. As a content editor, you’re navigating the daily challenge of maintaining quality while meeting deadlines and managing competing priorities.
When your team decides to prioritize website accessibility, the initial scope can feel daunting. You might wonder “Does this really make a difference?” or “Is remediation worth the effort?” The answer is always a resounding yes.
Whether you’re working on a small site or managing thousands of pages, accessible content improves user experience, ensures legal compliance, boosts SEO performance, and reinforces your brand as inclusive and responsible. As a content editor, you have the power to make steady, meaningful progress with the content you touch every day.
Why Accessibility Creates Business Impact
Accessible content delivers measurable outcomes across multiple business objectives:
Expanded Market Reach: When your content is inaccessible to users with disabilities, you’re limiting your potential audience. Consider that disabilities can be temporary, like a broken arm, and 70% of seniors are now online—a demographic that often benefits from accessible design principles.
Risk Mitigation: Inaccessible websites can lead to legal complaints under the ADA and other regulations, creating both financial and reputational risks.
Enhanced User Experience: Clear structure, descriptive alt text, and keyboard-friendly navigation improve usability for all users while boosting SEO performance.
Brand Differentiation: Demonstrating commitment to accessibility positions your organization as inclusive and socially responsible.
Implementing Accessibility in Your Editorial Workflow
The challenge isn’t whether to implement accessibility—it’s how to do it efficiently without overwhelming your team or budget.
The Fix-It-Forward Approach
Rather than attempting to overhaul your entire site overnight, we recommend a “fix-it-forward” strategy. This approach ensures all new and updated content meets accessibility standards while gradually improving legacy content. The result? Steady progress without resource strain.
Leverage Open Source Tools
Many CMS platforms offer free accessibility tools that integrate directly into your editorial workflow:
Drupal: Editoria11y Accessibility Checker, Accessibility Scanner, CKEditor Accessibility Auditor
WordPress: WP Accessibility, Editoria11y Accessibility Checker, WP ADA Compliance Check Basic
These tools scan your content and flag common WCAG 2.2 AA issues before publication, transforming accessibility checks into routine quality assurance.
Prioritize High-Impact Changes
Focus your efforts on fixes that significantly improve usability for screen reader and keyboard users:
- Missing image alt text
- Poor heading structure
- Duplicate or unclear link text
- Links that open new windows without warning
- Insufficient color contrast (may require developer collaboration)
Less critical issues can be addressed during routine content updates, spreading the workload over time.
Manage Legacy Content Strategically
Don’t let your content backlog create paralysis. Prioritize high-traffic pages and those supporting key user journeys. Since refreshing legacy content annually is already an SEO best practice, use these updates as opportunities to implement accessibility improvements.
Build Team Capabilities
Make accessibility part of your content culture through targeted education and resources. Provide internal training, quick reference guides, and trusted resources to keep editors confident and informed.
Recommended Learning Resources:
Track Progress and Celebrate Wins
Measure success by tracking pages published with zero critical accessibility issues. Share achievements in editorial meetings to reinforce your team’s impact and maintain momentum.
Scaling Your Accessibility Program
While regular content checks provide immediate value, sustainable accessibility success requires periodic comprehensive assessments and usability testing. If your team lacks bandwidth for advanced testing, consider adding this to your 1-2 year digital roadmap. Consistent attention over time proves more sustainable and cost-effective than attempting massive one-time remediation.
Start with Free Tools: Google Lighthouse provides immediate insights into accessibility issues and actionable remediation guidance.
Advanced Assessment Options: For teams ready to expand their program, tools like SortSite, SiteImprove, and JAWS screen reader testing offer comprehensive assessments. These advanced tools can uncover complex issues beyond content-level checks, though they may require developer collaboration for implementation.
Quarterly Program Goals:
- Regular Google Lighthouse assessments for incremental improvements
- Full-site scans or top-page audits with developer support
- Remediation prioritization based on traffic and business value
- Ongoing WCAG 2.2 AA compliance tracking
Consider engaging someone who navigates the web differently than your team does. This perspective will expand your understanding of accessibility’s real-world impact and inform more effective solutions.
Accessibility as Continuous Improvement
Accessibility isn’t a one-time project—it’s an ongoing commitment to inclusive digital experiences.
By integrating accessibility best practices into your publishing workflow, you’ll build a stronger, more inclusive website that protects your brand, empowers your users, and demonstrates digital leadership.
The fix-it-forward approach transforms what seems like an overwhelming challenge into manageable, sustainable progress.
Ready to Accelerate Your Accessibility Journey?
Explore additional insights from our team:
- More than Mouse Clicks: A Non-Disabled User’s Guide to Accessible Web Navigation
- How Does the European Accessibility Act Affect Your Business?
Ready to take action? Contact Oomph to see how we can support your accessibility journey. We start with targeted accessibility audits that identify your highest-impact opportunities, then collaborate with your team to develop a strategic roadmap that aligns with your internal goals while respecting your resources and team size.